
问题描述:
我用logstash收集日志,保存到elasticsearch
每天都会按日期建立新的索引。但是elasticsearch日志显示,建立索引之后,有错误日志,
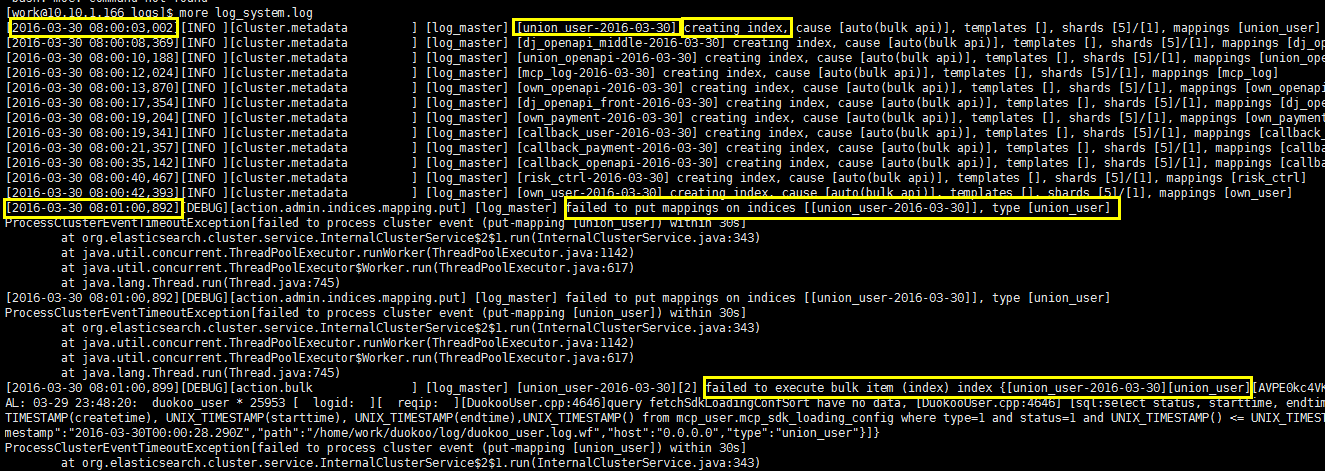
[2016-03-30 08:00:03,002][INFO ][cluster.metadata ] [log_master] [union_user-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [union_user]
[2016-03-30 08:00:08,369][INFO ][cluster.metadata ] [log_master] [dj_openapi_middle-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [dj_openapi_middle]
[2016-03-30 08:00:10,188][INFO ][cluster.metadata ] [log_master] [union_openapi-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [union_openapi]
[2016-03-30 08:00:12,024][INFO ][cluster.metadata ] [log_master] [mcp_log-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [mcp_log]
[2016-03-30 08:00:13,870][INFO ][cluster.metadata ] [log_master] [own_openapi-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [own_openapi]
[2016-03-30 08:00:17,354][INFO ][cluster.metadata ] [log_master] [dj_openapi_front-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [dj_openapi_front]
[2016-03-30 08:00:19,204][INFO ][cluster.metadata ] [log_master] [own_payment-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [own_payment]
[2016-03-30 08:00:19,341][INFO ][cluster.metadata ] [log_master] [callback_user-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [callback_user]
[2016-03-30 08:00:21,357][INFO ][cluster.metadata ] [log_master] [callback_payment-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [callback_payment]
[2016-03-30 08:00:35,142][INFO ][cluster.metadata ] [log_master] [callback_openapi-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [callback_openapi]
[2016-03-30 08:00:40,467][INFO ][cluster.metadata ] [log_master] [risk_ctrl-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [risk_ctrl]
[2016-03-30 08:00:42,393][INFO ][cluster.metadata ] [log_master] [own_user-2016-03-30] creating index, cause [auto(bulk api)], templates [], shards [5]/[1], mappings [own_user]
[2016-03-30 08:01:00,892][DEBUG][action.admin.indices.mapping.put] [log_master] failed to put mappings on indices [[union_user-2016-03-30]], type [union_user]
ProcessClusterEventTimeoutException[failed to process cluster event (put-mapping [union_user]) within 30s]
at org.elasticsearch.cluster.service.InternalClusterService$2$1.run(InternalClusterService.java:343)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
[2016-03-30 08:01:00,892][DEBUG][action.admin.indices.mapping.put] [log_master] failed to put mappings on indices [[union_user-2016-03-30]], type [union_user]
ProcessClusterEventTimeoutException[failed to process cluster event (put-mapping [union_user]) within 30s]
at org.elasticsearch.cluster.service.InternalClusterService$2$1.run(InternalClusterService.java:343)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
[2016-03-30 08:01:00,899][DEBUG][action.bulk ] [log_master] [union_user-2016-03-30][2] failed to execute bulk item (index) index {[union_user-2016-03-30][union_user][AVPE0kc4VKH7icABsVlx], source[{"message":"FAT
AL: 03-29 23:48:20: duokoo_user * 25953 [ logid: ][ reqip: ][DuokooUser.cpp:4646]query fetchSdkLoadingConfSort have no data, [DuokooUser.cpp:4646] [sql:select status, starttime, endtime, appids, channels, picpath, UNIX_
TIMESTAMP(createtime), UNIX_TIMESTAMP(starttime), UNIX_TIMESTAMP(endtime),UNIX_TIMESTAMP() from mcp_user.mcp_sdk_loading_config where type=1 and status=1 and UNIX_TIMESTAMP() <= UNIX_TIMESTAMP(endtime) ]","@version":"1","@ti
mestamp":"2016-03-30T00:00:28.290Z","path":"/home/work/duokoo/log/duokoo_user.log.wf","host":"0.0.0.0","type":"union_user"}]}
ProcessClusterEventTimeoutException[failed to process cluster event (put-mapping [union_user]) within 30s]
求各位大神帮忙解答一下,是哪里的原因






