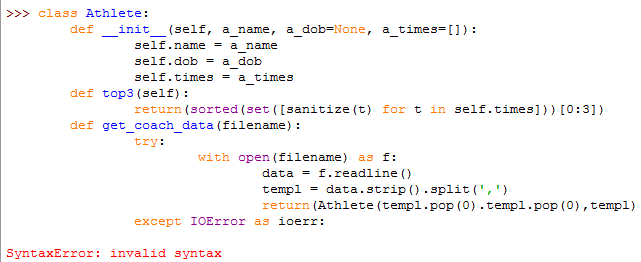
提示except出错,到底为什么

python3代码出现错误,怎么解决

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新

- 2022-08-23 16:00回答 1 已采纳 导入了太多没有用的模块,参考我的代码: import requests #发送HTTP请求 from bs4 import BeautifulSoup headers ={ "User-Age
- 2023-03-20 18:46回答 4 已采纳 time data '' does not match format '%Y-%m-%d %H:%M:%S' data_string 是一个空字符串,导致转换异常了。
- 2023-04-19 16:52回答 4 已采纳 input()返回的是字符串类型,所以才能用input().split()所以abcdef都是字符串。所以j = abc.... 出现了字符串乘字符串。咋改呢?abcedf再转换一下格式呗。
- 2020-12-03 05:08weixin_39551993的博客 python常见的错误有1.NameError变量名错误2.IndentationError代码缩进错误3.AttributeError对象属性错误详细讲解1.NameError变量名错误报错:解决方案:先要给a赋值。才能使用它。在实际编写代码过程中,报NameError...
- 2022-07-09 15:07回答 3 已采纳 你那个:是中文的吧
- 2022-09-05 15:36回答 1 已采纳 应该是datetime. datetime.now()
- 2022-02-17 14:39回答 2 已采纳 删掉第一行和最后一行,a是直接通过输入语句定义的变量,不需要赋初值。 a = input() print(ord(a))
- 2021-02-03 06:47Michael Tu的博客 Python2代码转Python3代码教程由于尤其是跑一些神经网络的代码时有很多是在 Python2 的环境下写的。在 Python3 下运行会遇见很多不兼容。Python2代码转Python3代码Python2 代码转 Python3 代码的一种方式是再安装一...
- 2022-10-20 16:29回答 3 已采纳 a = np.array,这不是都写对了吗b = np.arary,这么明显的拼写错误,错误信息都给你打印出来了,你是对字母有多不敏感
- 2022-03-26 21:23回答 1 已采纳 我感觉 A , B 的维度没那么大 建议你看看new_mutiple这个函数的逻辑和算法,对照检查一下 红框的内容也可以跟踪一下
- 2022-03-28 21:05一颗星星吖的博客 今天师姐给了一个说话人识别的代码,打开发现全是错误,print语句全是错的,我没有学习过python2的语法,但是也猜到了可能是代码太老了,需要转换一下。但是手动去改的话,太多了。下面介绍一种自动改的方法: 1、...
- 2021-11-21 15:36陪计算机走过漫长岁月的博客 go-python3使用指南与踩坑记录 简介 好久没有更新博客了,笔者毕业一年多了,在国内某大厂工作,最近在工作过程中接到了一个颇有挑战感的活,在解决过程中发现网上对这方面的学习资料还是有所欠缺,所以特地记录...
- 2020-11-21 02:12weixin_39922394的博客 做任何语言的编程都会报错,Python也不例外,遇到语法错误不可怕,只要按照一定的方法解决就行,Python中可能会出现两种不同种类的报错,今天小码王老师给小朋友们介绍这两种Python中出现语法错误时解决方法,小朋友...
- 2020-12-11 09:38weixin_39888807的博客 很多数据不可避免的会遗失掉,或者采集的时候采集对象不愿意透露,这就造成了很多NaN(Not a Number)的出现。这些NaN会造成大部分模型运行出错,所以对NaN的处理很有必要。解决方法:1、简单粗暴地去掉1)有如下...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 如何在scanpy上做差异基因和通路富集?
- ¥20 关于#硬件工程#的问题,请各位专家解答!
- ¥15 关于#matlab#的问题:期望的系统闭环传递函数为G(s)=wn^2/s^2+2¢wn+wn^2阻尼系数¢=0.707,使系统具有较小的超调量
- ¥15 FLUENT如何实现在堆积颗粒的上表面加载高斯热源
- ¥30 截图中的mathematics程序转换成matlab
- ¥15 动力学代码报错,维度不匹配
- ¥15 Power query添加列问题
- ¥50 Kubernetes&Fission&Eleasticsearch
- ¥15 報錯:Person is not mapped,如何解決?
- ¥15 c++头文件不能识别CDialog