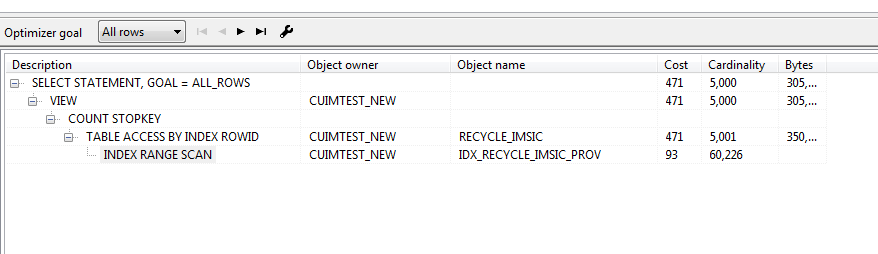
select * from (select my_table.*,rownum as my_rownum from(
select
a.iccid,
a.batch_id,
a.imsi_c as imsi_x,
a.state_date as create_date,
'IMSL' as imsi_x_type
from recycle_imsic a
where a.c_state='3' and a.province_id='12'
)
my_table where rownum< 5001) where my_rownum>= 1

oracle sql查询效率慢

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


4条回答 默认 最新
悬赏问题
- ¥15 用visual studi code完成html页面
- ¥15 聚类分析或者python进行数据分析
- ¥15 逻辑谓词和消解原理的运用
- ¥15 三菱伺服电机按启动按钮有使能但不动作
- ¥15 js,页面2返回页面1时定位进入的设备
- ¥50 导入文件到网吧的电脑并且在重启之后不会被恢复
- ¥15 (希望可以解决问题)ma和mb文件无法正常打开,打开后是空白,但是有正常内存占用,但可以在打开Maya应用程序后打开场景ma和mb格式。
- ¥20 ML307A在使用AT命令连接EMQX平台的MQTT时被拒绝
- ¥20 腾讯企业邮箱邮件可以恢复么
- ¥15 有人知道怎么将自己的迁移策略布到edgecloudsim上使用吗?