机子上已经安装了cuda7.5,torch也安装成功,然后在安装cutorch时 ,遇到如下报错,请问有盆友也遇到过同样的问题吗?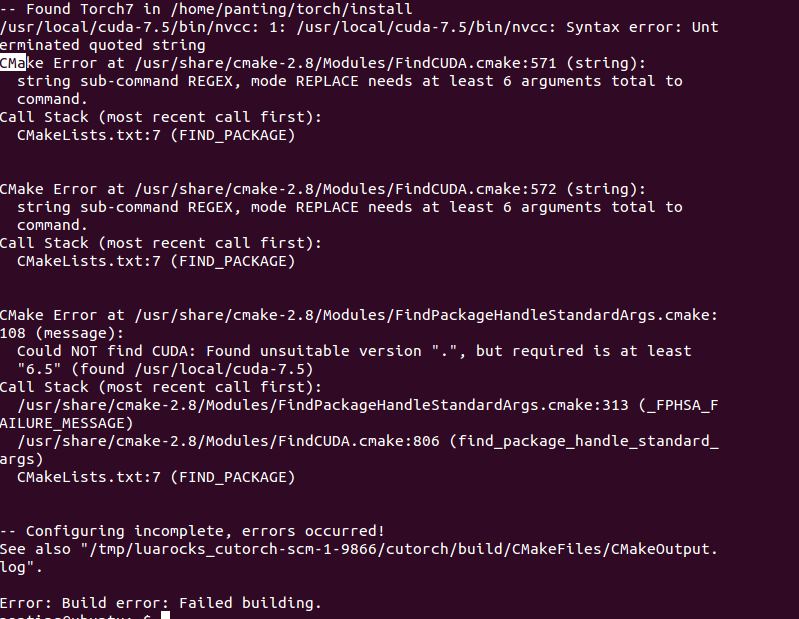

torch7搭建时luarocks install cutorch 报错

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2020-07-07 23:25ZhangLH66的博客 问题:pip install torch报错 ModuleNotFoundError: No module named 'tools.nnwrap' error: [Errno 2] No such file or directory: ‘.gitignore’ ModuleNotFoundError: No module named ‘tools.nnwrap’ 解决...
- 2024-01-10 17:09钰醂的博客 安装torch-scatter和torch-cluster报错:pip install torch-cluster。
- 2021-01-20 03:23Pycharm中import torch报错的解决方法 问题描述: 今天在跑GitHub上一个深度学习的模型,需要引入一个torch包,在pycharm中用pip命令安装时报错: 于是我上网寻求解决方案,试了很多都失败了,最后在:Anne琪琪的...
- 万粉变现经纪人的博客 摘要:本文针对PyCharm控制台运行import torch时出现的ModuleNotFoundError问题,详细分析了九种常见原因及解决方案,包括未安装包、网络问题、包名冲突、PYTHONPATH配置错误等。文章提供了切换国内镜像源、升级pip...
- 2019-10-30 20:54诸葛日天博士的博客 为了复现一个16年的文章代码,搭建torch 尝试了网上所说的各种方案。统统不管用!可能是服务器无法翻墙 (1)luarocks install loadcaffe 显示 【 Warning: Failed searching manifest: Failed fetching manifest ...
- 2022-06-21 14:53瓦坎达耍杂技的的博客 解决Mac import torch-geometric时报错问题。
- 2020-09-04 15:01知识海洋里的咸鱼的博客 torch.utils.tensorboard import SummaryWriter报错 已安装pytorch1.2、tensorflow1.9和tensorboard1.9,在导入SummaryWriter的时候显示不存在该模块。 不存在的原因预计是pytorch和tensorboard0的版本过低,因此...
- 2022-03-17 20:53氵文大师的博客 大概是这么个报错法,用torch这么些年,第一次碰见这个错NotImplementedError 我用的也不是什么 nightly 版本啊 Traceback (most recent call last): File "xxxxx\x.py", line 268, in <module> print(x(y)...
- 2023-07-24 20:50聆蝉鸣的博客 问题 在cmd命令提示符中import torch正常,Jupyter却失败并报错为No module……、 解决方法 conda install jupyter #重新安装Jupyter conda install nb_conda_kernels #安装相对应的模块 再次尝试,可以...
- 2015-05-27 09:00feng_blog6688的博客 1、before intallation,you should install node.js,gfx.js Node.js是一个软件平台,通常用于构建大规模的服务器端应用。Node.js使用JavaScript作为其脚本语言,由于其非阻塞I/O设计以及单线程事件循环机制,使得...
- 2022-03-04 11:05qq_42790946的博客 importtorch不出错,但是import torchvision报错:UserWarning: Failed to load image Python extension: Could not find module 网上看了看一般是torch和torchvision版本不匹配,但我看那个对照表我的版本是正常...
- 2022-12-17 16:31波尔德的博客 from torch.utils.tensorboard import SummaryWriter 报错:ModuleNotFoundError: No module named 'tensorboard
- 没有解决我的问题, 去提问

