从论坛里面大家说是改core-site.xml,问题是我不管怎么该,最终格式化的还是/tmp下的目录,而不是我指定的目录,请各位大神给点意见,谢谢!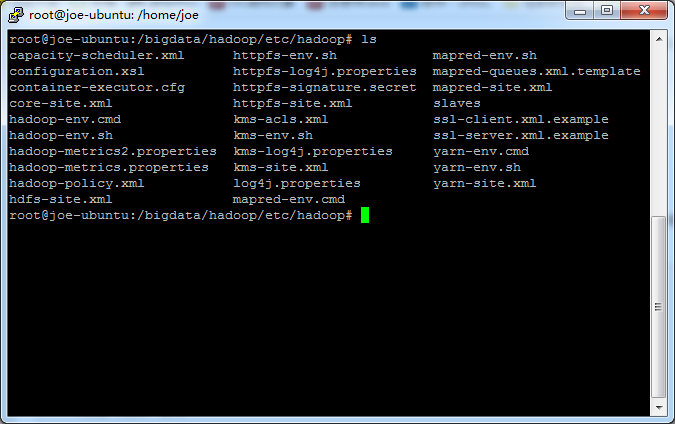
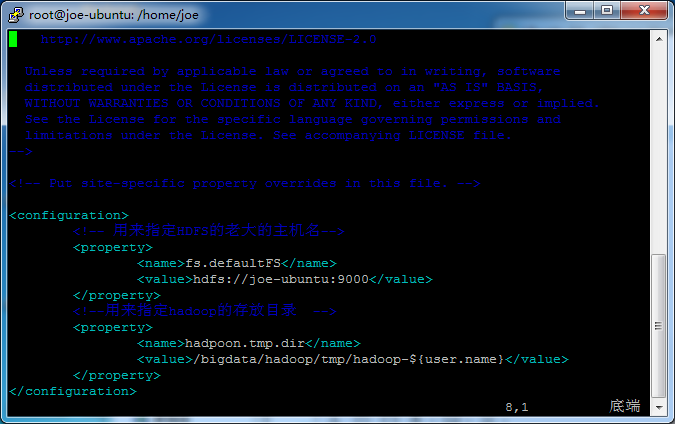
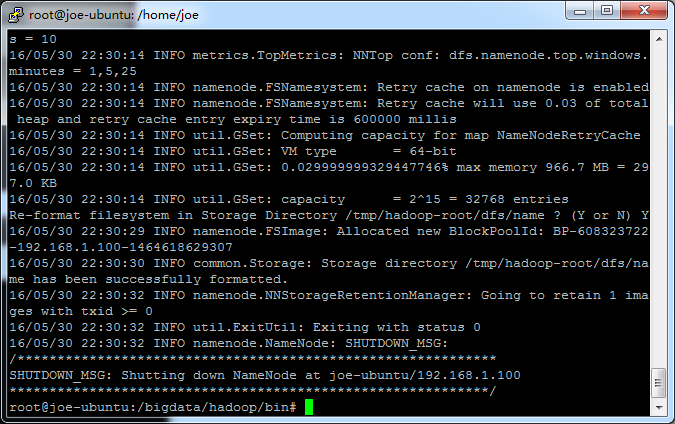
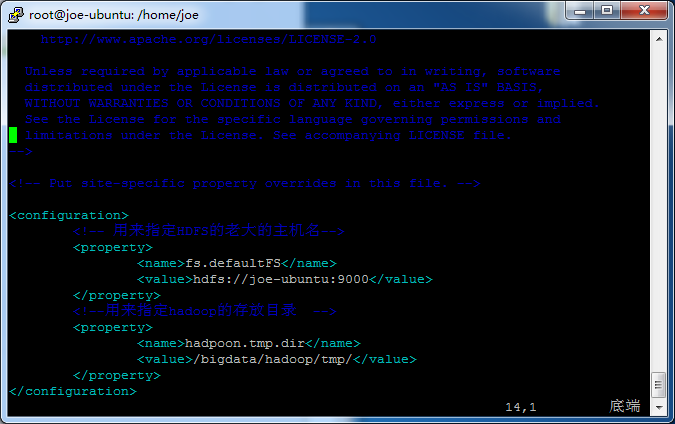

hadoop伪分布式时,为什么namenode每次都要重新格式化

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
- Joe_Y_Zhou 2016-05-30 15:56关注
原来配置名字写错,一直没发现,知了
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2019-12-23 19:18Alaskyed的博客 Hadoop伪分布式的搭建和重复格式化namenode的问题解决Hadoop伪分布式Hadoop伪分布式介绍Hadoop伪分布式的搭建HDFS伪分布式搭建yarn伪分布式搭建重复格式化namenode产生的问题及其解决方法 Hadoop伪分布式 Hadoop伪...
- 2023-05-09 00:18LZ7工作室的博客 【代码】Hadoop伪分布式配置教程。
- 2024-08-02 11:10Felix...的博客 伪分布式模式也是在一台单机上运行,集群中的结点由一个NameNode和若干个DataNode组,另有一个SecondaryNameNode作为NameNode的备份。一个机器上,既当namenode,又当datanode,或者说既是jobtracker,又是...
- 2023-10-04 03:43AsfSql的博客 在Hadoop的伪分布式环境中,启动集群之前需要进行一些...在Hadoop伪分布式环境中,每次启动集群之前都需要重新格式化HDFS。命令来检查集群的状态。记住,在重新格式化HDFS之前,请确保备份了重要的数据,以免数据丢失。
- 2018-05-31 21:24lqy0927的博客 【Ubuntu 16.04 Hadoop2.9.1】跟着厦大林子雨的实验指南配置伪分布式环境时出现了以下问题:在修改了/etc/hadoop/core-site.xml & /etc/hadoop/hdfs-site.xml后namenode -format时出现 Cannot create ...
- 2025-04-17 09:50我不是秋秋的博客 Hadoop 伪分布式安装是一种在单台物理机器上模拟分布式集群环境的部署方式。分布式服务启用:运行 Hadoop 的所有核心组件(如 HDFS 的 NameNode、DataNode,YARN 的 ResourceManager、NodeManager 等),但所有组件...
- 2021-05-22 11:335. 初始化HDFS命名空间,格式化NameNode。 6. 启动Hadoop服务,包括DataNode、NameNode和ResourceManager等。 7. 最后,通过`help文档.txt`中的指示进行验证,确保Hadoop伪分布式环境已成功搭建并运行。 理解并掌握...
- 2024-04-20 19:12YYY7769的博客 在这个文件最后换行添加如下三行:vi /etc/profile # JDK export JAVA_HOME=/opt/jdk ...export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin进行免密登录需要安装ssh如果有openssh-clients、openss
- 2024-09-20 18:11人生百态,人生如梦的博客 在进⾏存储和计算时,将涉及到的相关守护进程都运⾏在同⼀台机器上,它们都是独⽴的 Java进程,因⽽称为“伪分布式集群”。伪分布式集群模式,⽐本地模式多了代码调试功能,允许检查内存的使⽤、HDFS输⼊输出、以及 ...
- 2020-10-07 08:46在搭建过程中,可能会遇到配置文件未保存、NameNode格式化失败等问题。这些问题通常通过检查配置文件的语法、删除错误配置并重新格式化NameNode,以及确保所有输入都使用英文输入法即可解决。 总结来说,Hadoop伪...
- 没有解决我的问题, 去提问

