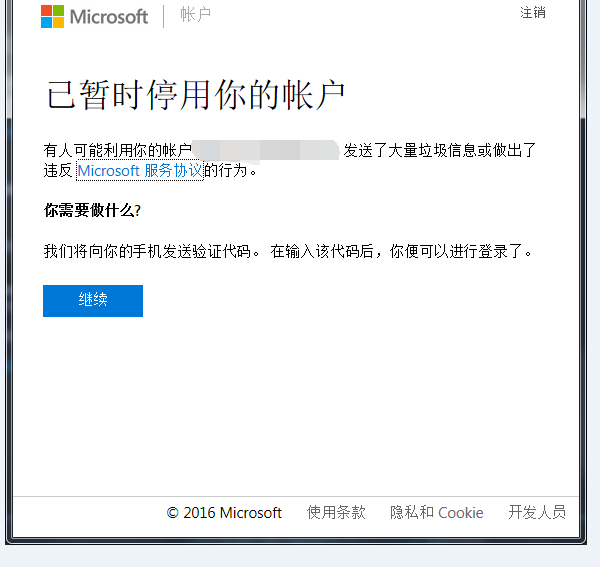
 求解:如图 我今天想登账户看看 结果发现成这样了 我也没干什么事
求解:如图 我今天想登账户看看 结果发现成这样了 我也没干什么事

为什么我的微软账户被暂时停用

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

悬赏问题
- ¥20 腾讯企业邮箱邮件可以恢复么
- ¥15 有人知道怎么将自己的迁移策略布到edgecloudsim上使用吗?
- ¥15 错误 LNK2001 无法解析的外部符号
- ¥50 安装pyaudiokits失败
- ¥15 计组这些题应该咋做呀
- ¥60 更换迈创SOL6M4AE卡的时候,驱动要重新装才能使用,怎么解决?
- ¥15 让node服务器有自动加载文件的功能
- ¥15 jmeter脚本回放有的是对的有的是错的
- ¥15 r语言蛋白组学相关问题
- ¥15 Python时间序列如何拟合疏系数模型