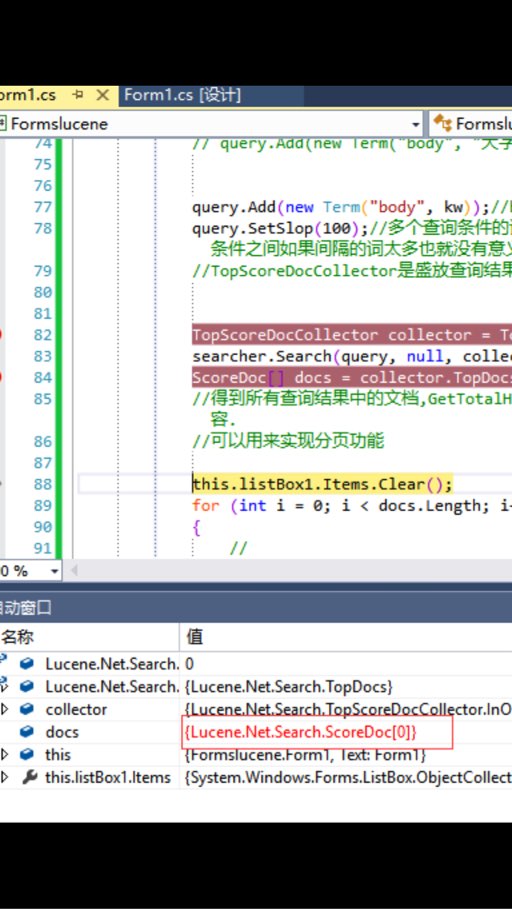
Lucene的scoredoc[]这个集合一直都是空!查询的词文本文件里确定是有的,望大什么指教下,多谢多谢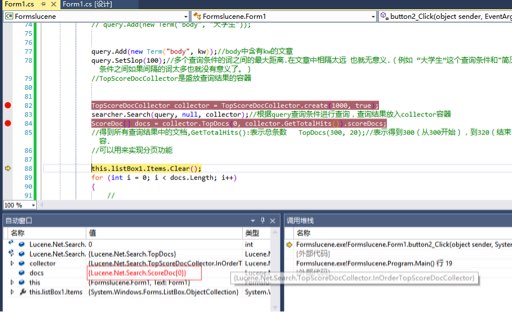

Lucene.net盘古查可是怎么也查不出来

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

- 2016-05-06 06:08回答 1 已采纳 是中文么,中文需要分词。 参考:http://www.cnblogs.com/lhj588/archive/2013/02/06/2900937.html
- 2017-07-03 05:19回答 2 已采纳 我猜想分词出现的问题,你可以下个luke去查看分词的情况
- 2015-08-24 08:57回答 1 已采纳 运行你的程序,在浏览器中点查看源代码 贴出对应的代码,看看什么问题
- 2020-09-13 16:46Lucene.Net +盘古分词 搜索引擎,Lucene.Net2.9.4.版本,vs2012开发,通过实例可以有初步的认识和了解
- 2022-11-27 15:54回答 1 已采纳 你看下这篇博客吧, 应该有用👉 :Lucene+springboot 实现一个简单的搜索
- 2014-10-19 12:24回答 1 已采纳 建议直接用solr或者es。想精确查找,对应的索引字段应不分词,模糊就分词。
- 2013-09-20 10:06回答 1 已采纳 查询用* ,还要看你是什么版本
- 2021-04-27 03:00使用visual studio 开发的lucene.net和盘古分词实现全文检索。并按照lucene的得分算法进行多条件检索并按照得分算法计算匹配度排序。 可以输入一句话进行检索。 lucene.net的版本为2.9.2 盘古分词的版本为2.3.1 并...
- 2015-08-31 10:01回答 1 已采纳 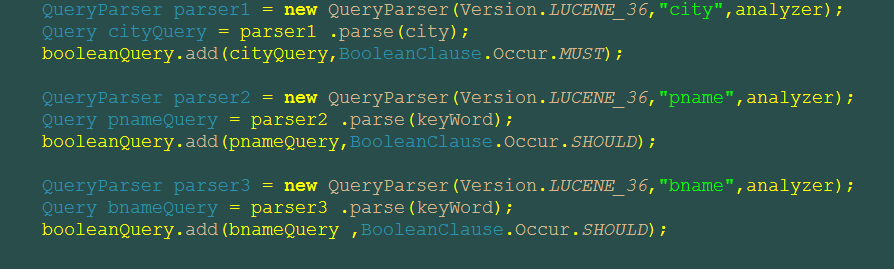 我现在这么写的效果是and es.city=1031
- 2008-08-04 20:34回答 1 已采纳 a 是StandardAnalyzer的默认stopword,会被过滤掉,所以你搜索不出来内容。 要么换个analyzer,要么用个别的词做测试。 ps:你的lucene版本也太老了点。
- 2013-05-06 14:20回答 1 已采纳 方案1: 你修改的数据 加一个触发器 如果你要索引的字段被改动后 把id插入另一张表里 然后跑定时任务 根据这些ID查找出要索引的数据 定时的构建索引 然后再把这些IDdelete掉 方案2
- 2021-11-02 18:22工厂将所有LOG放在共享盘里面,用这个来找超级快.
- 2010-08-12 13:56回答 2 已采纳 I've searched google for you : The default boolean operator may be set or retrieved with the Zend
- 2022-10-11 14:09lijingguang的博客 Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。开发人员可以基于Lucene.net实现全文检索的...
- 2019-01-14 18:13Lucene.Net+盘古分词是一个常见的中文信息检索组合。但是随着盘古分词停止更新,与Lucene.Net3.0无法兼容。为了使得大家少走弯路,本人利用Lucene.Net2.9+盘古分词2.3搭建了一个Demo,里面包含了两个模块的源码,方便...
- 没有解决我的问题, 去提问



悬赏问题
- ¥50 导入文件到网吧的电脑并且在重启之后不会被恢复
- ¥15 (希望可以解决问题)ma和mb文件无法正常打开,打开后是空白,但是有正常内存占用,但可以在打开Maya应用程序后打开场景ma和mb格式。
- ¥15 绘制多分类任务的roc曲线时只画出了一类的roc,其它的auc显示为nan
- ¥20 ML307A在使用AT命令连接EMQX平台的MQTT时被拒绝
- ¥20 腾讯企业邮箱邮件可以恢复么
- ¥15 有人知道怎么将自己的迁移策略布到edgecloudsim上使用吗?
- ¥15 错误 LNK2001 无法解析的外部符号
- ¥50 安装pyaudiokits失败
- ¥15 计组这些题应该咋做呀
- ¥60 更换迈创SOL6M4AE卡的时候,驱动要重新装才能使用,怎么解决?