我的虚拟机搭建了HDFS一个集群完全分布式,在win7系统下安装Eclipse插件,运行MapReduce程序报错,好像是连接不上,求大神帮忙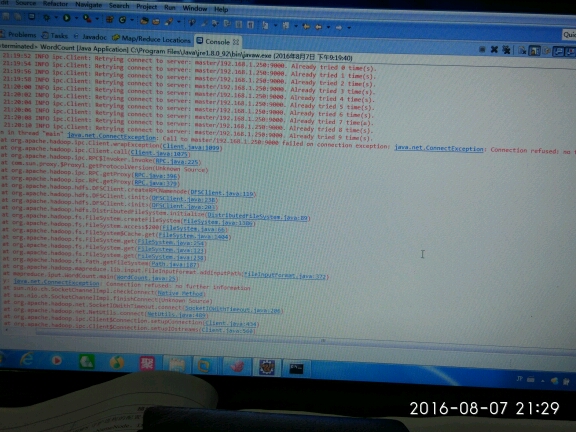

Hadoop安装插件运行MapReduce报错

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

- 2017-09-06 01:16回答 1 已采纳 http://blog.csdn.net/jack85986370/article/details/51902871
- 2022-01-04 19:58回答 3 已采纳 单机版的不可缺少namenode和datanode,如果是集群,只要保证一台有namenode即可,建议将所有的进程全部停掉,然后从新启动,可以使用start-all.sh,当然分开的话也可以使用st
- 2017-09-09 08:20回答 1 已采纳 http://blog.csdn.net/crazyzhb2012/article/details/9258247
- 2019-10-02 20:47weixin_30883311的博客 根据http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/进行下载安装 ...经查询,是Hadoop-Eclipse-Plugin插件安装失败。 解决办法:将hadoop2x-eclipse-plugin-master.zip放在我开始新建的共...
- 2021-12-04 16:26回答 1 已采纳 你代码中获取了args中的参数,这个是需要配置的。如果觉得麻烦,直接将代码中涉及args[]取值的地方替换为具体的值。 idea中运行args作为接收参数的程序_Luke
- 2022-05-20 13:43回答 2 已采纳 从报错来看,是一个循环依赖的问题,类似于 A 依赖 B, B依赖C ,C依赖A;可以先排查一下jar的依赖!
- 2021-11-04 17:10回答 1 已采纳 根据报错信息:Exception in thread "main" java.langNoClassDefFoundError: org/apache/hadoop/yarn/util/Apps 可
- 2022-03-08 18:58Jumanji_的博客 Hadoop(四)MapReduce
- 2022-03-23 16:55回答 1 已采纳 是端口号的问题吗你将报错的信息百度一下
- 2022-10-03 13:52回答 1 已采纳 把光标挪到最后一个输入框(Oozie的URL)中,使用Tab来挪光标,然后回车试试。
- 2021-12-05 08:26回答 1 已采纳 数组越界了,从0开始访问,到3,java.lang.StringIndexOutOfBoundsException: String index out of range: 4你这个访问了4
- 2021-02-27 21:04黄之昊的博客 最近安装了hadoop的0.20.2 版本,然后再eclipse中安装了 对应的插件,在运行 示例中的 程序 WordCount.java 的时候,出现了很多错误:1. 配置连接的 hadoopLocation name(取个名字)Map/Reduce Master(Job Tracker的...
- 2023-04-09 21:34回答 1 已采纳 你的数据节点没有找到,所以没法计算,还是配置的问题,好好检查检查
- 2019-06-18 17:18zhamors的博客 实验环境:Red Hat 6.5、...1.Hadoop安装实验 准备工作 配置主机名 更改主机名方法: 查看自己虚拟机的IP地址 修改每台服务器上的/etc/hosts文件,添加主机名配置。 安装配置JDK Red ...
- 2021-12-28 09:38是xunxun啊的博客 本文介绍了将单机模式的wordcount部署到hadoop集群上需要注意的问题,并给出了VMware虚拟机CentOS7突然没有ens33,2.3 GB of 2.1 GB virtual memory used. Killing container.这两个问题的部分解决办法
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 drone 推送镜像时候 purge: true 推送完毕后没有删除对应的镜像,手动拷贝到服务器执行结果正确在样才能让指令自动执行成功删除对应镜像,如何解决?
- ¥15 求daily translation(DT)偏差订正方法的代码
- ¥15 js调用html页面需要隐藏某个按钮
- ¥15 ads仿真结果在圆图上是怎么读数的
- ¥20 Cotex M3的调试和程序执行方式是什么样的?
- ¥20 java项目连接sqlserver时报ssl相关错误
- ¥15 一道python难题3
- ¥15 牛顿斯科特系数表表示
- ¥15 arduino 步进电机
- ¥20 程序进入HardFault_Handler