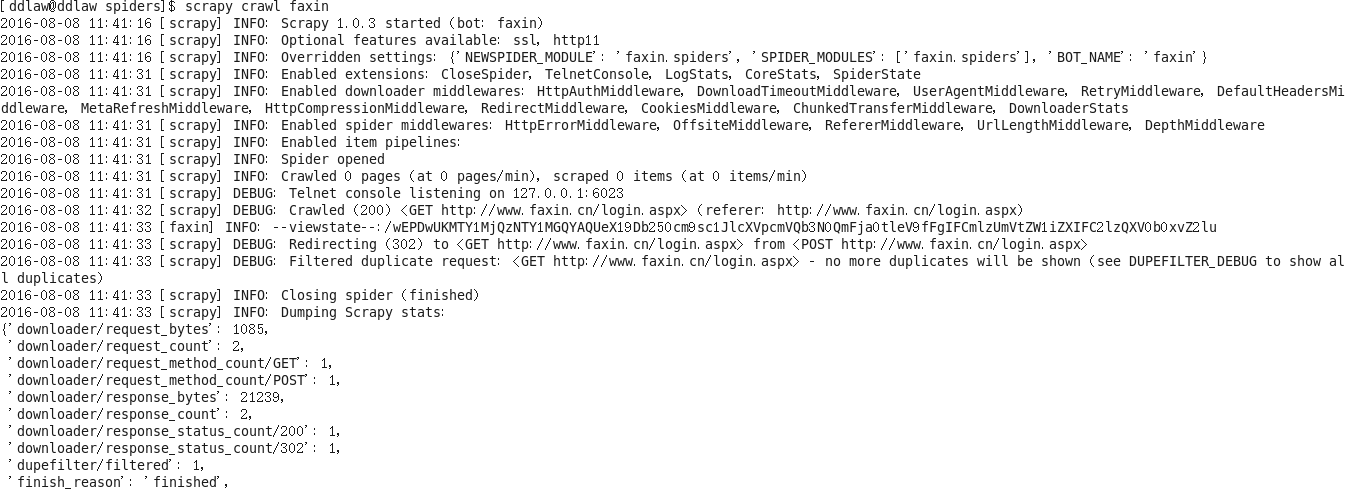
scrapy模拟登陆不能抓取到数据
模拟登陆没有跳转到抓取页面
真实去登陆账号不能再次的登陆了
不知道问题出在哪里求大神解答
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
from scrapy.selector import Selector
from scrapy.conf import settings
class faxinSpider(scrapy.Spider):
name = "faxin"
allowed_domains = ["www.faxin.cn"]
start_urls = ["http://www.faxin.cn/keyword/index.aspx"]
headers = settings.get('HEADERS')
def start_requests(self):
return [Request(
url = "http://www.faxin.cn/login.aspx",
meta = {'cookiejar' : 1},
headers = self.headers,
callback=self.post_login
)]
def post_login(self, response):
viewstate = Selector(response).xpath('//input[@name="__VIEWSTATE"]/@value').extract()[0]
self.logger.info("--viewstate--:%s", viewstate)
return [FormRequest.from_response(
response,
meta = {'cookiejar' : response.meta['cookiejar']},
headers = self.headers,
formdata = {
'__VIEWSTATE' : viewstate,
'WebUCHead_Special1$hiddIsLogin' : '0',
'user_name' : '****',
'user_password' : '****'
},
callback = self.pares_page,
)]
def after_login(self, response):
for url in self.start_urls :
yield Request(url,
headers = self.headers,
meta = {'cookiejar' : response.meta['cookiejar']},
callback = self.pares_page)
def pares_page(self, response):
url_ = response.url
self.logger.info("---url---: %s", url_)
# a = Selector(response).xpath("//a[@class='login']/@title")
# self.logger.info("---username---: %s", a)
a_ = Selector(response).xpath("//div[@class='t_box']/ul[@class='clearfix']/li")
for a in a_:
print a.xpath("a/@href").extract()[0]