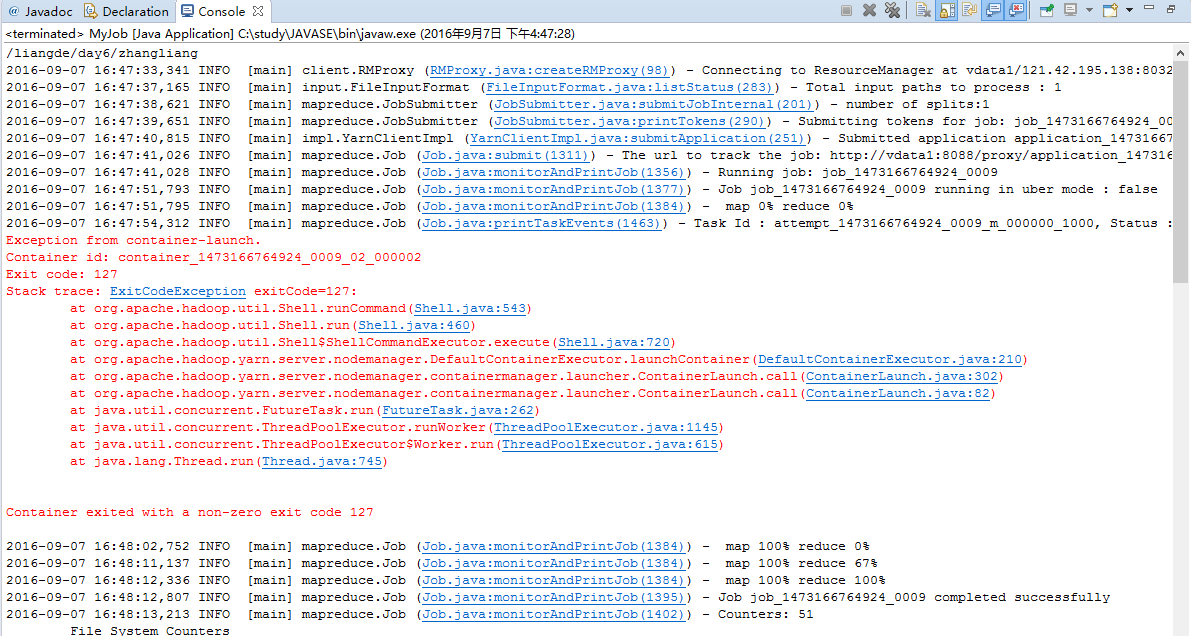

Hdoop MapReduce Partition 能运行,但报异常

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2024-06-19 21:56生产队队长的博客 Hadoop
- 2026-02-16 14:41之歆的博客 MapReduce是一种分布式计算框架,通过"分而治之"的思想将大数据处理任务分解为Map(并行处理)和Reduce(汇总结果)两个阶段。它通过将计算任务分配给集群中的多个节点并行执行,显著提高了大数据处理效率...
- 2021-02-26 15:27Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一分组的数据交给同一个Reducer处理,它直接影响Reduce阶段的负载均衡。...MapReduce提供了两个Partitioner实现:HashPartitioner和Total
- 2020-01-29 10:58zuodaoyong的博客 1、HashPartitioner(Hadoop自带的默认分区) 默认分区是根据key的HashCode对ReduceTasks个数取模得到的,用户无法控制具体的key存储到哪个分区 HashPartitioner源码如下: public class HashPartitioner<K, ...
- 2026-02-27 16:56Seal^_^的博客 Hadoop MapReduce编程模型深度解析:从分片到输出的完整流程 引言 一、MapReduce整体流程概览 1.1 你的描述验证 二、Map阶段详解 2.1 输入分片与读取 2.2 Mapper实现 2.3 Hadoop内置数据类型 三、分区(Partition)...
- 2019-02-28 11:42蜜叶的博客 在hadoopMR中,许多人的理解就是partition和reduceTask的关系就是一对一,这样理解没错,通常情况下reduceTask的数量和partition就是一对一的关系,但是他们不是绝对一对一的关系,reduceTask的数量由job提交时设置...
- 2022-05-08 20:05金融小码的博客 文章目录Hadoop MapReduce一、理解MapReduce思想二、Hadoop MapReduce设计构思(1)如何对付大数据处理场景(2)构建抽象编程模型(3)统一架构、隐藏底层细节三、Hadoop MapReduce介绍分布式计算概念MapReduce介绍...
- 2023-02-26 17:39海星?海欣!的博客 Hadoop MapReduce
- 2019-05-13 22:43SK_Jaco的博客 MapReduce作业提交拥有客户端、YARN资源管理器、YARN节点管理器、application master和File System五个独立实体组成,通过调用Job对象的waitForCompletion()方法提交作业,waitForCompletion方法用于提交以前...
- 2023-02-25 14:23健鑫.的博客 MapReduce 核心功能就是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的 分布式运算程序,并发运行在一个 Hadoop 集群上。序列化就是将内存中对象转换成字节序列,便于存储到磁盘和网络传输反序列化时将...
- 没有解决我的问题, 去提问

