ubuntu 16.04
hadoop 2.6.0
初始化 hadoop namenode -format
报错说找不到namenode,但是我的环境变量配置的好像没问题啊。。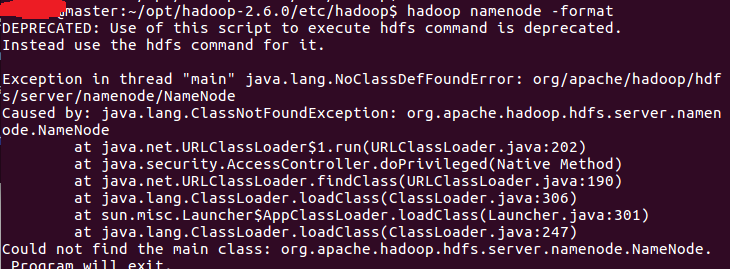
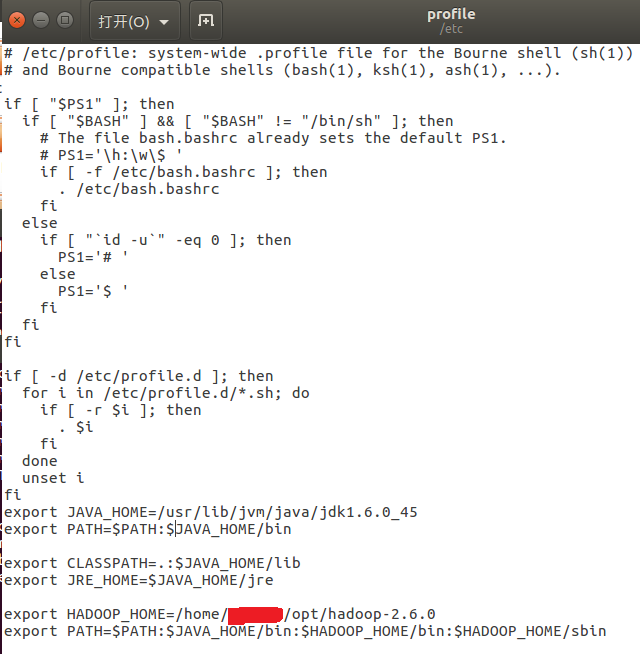
求大神赐教

hadoop 格式化namenode报错

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 hijack00 2016-09-11 13:29关注
hijack00 2016-09-11 13:29关注使用hadoop classpath命令查看hadoop当前配置的classpath路径,这样可以确定hadoop配置是不是有问题。
此外,将log4j.properties文件中的LogLevel设置为DEBUG,重点关注日志中的WARN和ERROR,这样可能会找到出错原因。解决 无用评论 打赏举报 分享
- 2023-08-23 14:04Kukukukiki192的博客 首次启动Hadoop集群, 格式化NameNode时报错。
- 2023-04-02 16:54小肆无忌惮的博客 Re-format filesystem in Storage Directory root= /usr/local/hadoop/tmp/dfs/name; location= null ? (Y or N) Y
- 2023-10-13 10:06Keep Doing this的博客 这个bug很搞笑,我做分布式搭建时,slaver1和slaver2都可以hadoop name -format,就是master不可以,配置都是一样的,这个第一时间也是想到了环境配置问题。这里的/apps/hadoop是我的hadoop...发现可以成功格式化了。
- 2019-01-18 10:54mapleting的博客 STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 826afbeae31ca687bc2f8471dc841b66ed2c6704; compiled by 'ajisaka' on 2018-11-13T12:42Z STARTUP_MSG: java = 1.8.0_65 ****...
- 2015-05-13 10:09shouwangV6的博客 今天在安装hadoop2.6.0时格式化namenode时报错 15/05/12 18:28:19 INFO ipc.Client: Retrying connect to server: hadoop3/192.168.110.139:8485. Already tried 0 time(s); retry policy is ...
- 2021-11-12 22:38寧三一的博客 一、重新格式化 NameNode 1、删除hadoop 三台节点配置路径下的残留文件 (1)core-site.xml 删除/usr/local/src/hadoop/tmp目录 (2)hdfs-site.xml 删除/usr/local/src/hadoop/dfs/name目录 (3)hdfs-site....
- 2020-09-19 16:54白嫖叫上我的博客 可以看到,格式化因为无法创建目录而报错:“Exitting with status 1” 解决: 1.按CTRL+ALT+T进入终端 2.输入命令:sudo su转为root身份 3.输入命令:sudo chmod -R a+w /绝对路径 4.重新进入终端使用普通用户身份...
- kyrie_rlving的博客 hadoop初始化namenode失败,报错:org.apache.hadoop.hdfs.qjournal.client.Quorumexception
- 2021-08-02 15:58天涯问路的博客 Hadoop 格式化的时候报错:dfs.namenode.format.enable false。 此时启动集群会发现 Namenode 无法启动,其实就是 Namenode 格式化失败了。 原因:很有可能是你们公司在编译 hadoop 的时候故意把格式化功能注释掉...
- 2020-07-17 13:56小妖盖的博客 我想格式化bin\hadoop目录下的namenode 然后最下面也没有命令成功的提示 在网上也没有搜到有效的解决方法,后来自己又重新输入了命令发现出现了成功的提示信息
- 没有解决我的问题, 去提问
