在抓取https://mm.taobao.com/search_tstar_model.htm?spm=719.1001036.1998606017.2.4Cf8Nt
的时候发现::before和::after之间的元素抓取不到,通过BeautifulSoup解析出来的对象中寻找不到"li"标签。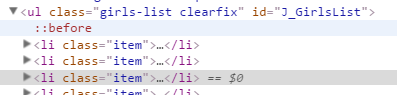
请问这是“::before”引起的问题吗?如果是,如何解决?如果不是,可能是什么问题?
期待回复,谢谢!

用python抓取爬虫时无法抓取::before与::after之间的内容

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新
 oyljerry 2016-10-06 04:23关注
oyljerry 2016-10-06 04:23关注可能是Ajax异步加载的。需要用selenium等模拟浏览器
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2016-10-06 03:24回答 3 已采纳 可能是Ajax异步加载的。需要用selenium等模拟浏览器
- 2022-07-23 12:09
 Python爬虫时遇到问题:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
json
python
爬虫
回答 3 已采纳
Python爬虫时遇到问题:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
json
python
爬虫
回答 3 已采纳 - 2022-06-04 10:47回答 1 已采纳 import sqlite3 import re import requests from lxml import html findlink = re.compile(r'<a href=
- 2021-04-11 13:13Jughead_Chen的博客 Python网络爬虫(一):安装开发环境及爬虫基础 一、安装 学习Python网络爬虫要有一定Python基础,本系列重点在网络爬虫,不讲述Python基础,需要学习Python基础的可以参考以下链接网站: 菜鸟教程:...
- 2019-07-02 18:16回答 1 已采纳 没用过select,但看样子是这样用的 ``` from bs4 import BeautifulSoup import requests url = 'http://bj.xiaozhu
- 2022-10-23 22:38回答 2 已采纳 urlopen里面的逗号改为.是.format有帮助的话采纳一下哦!
- 2021-11-27 22:00回答 2 已采纳 你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。requests只能获取网页的静态源代码,动态更新的内容取不到。对于动态更新的内容要用selenium 来爬取。 或者是通
- 2023-11-08 13:17JinDao.的博客 对第一次爬取数据得到的链接进行二次处理meta:添加字典属性,将指定的字典发送给二级爬虫方法的response对象里name = ''......yield item携带cookies请求重写start_requests方法, 构造请求携带cookiename = ''url =...
- 2022-08-25 15:41回答 3 已采纳 这并不是过长导致的,这是格式错误,参考下面步骤,不用一个一个手写参数,直接生成所有请求参数代码就不会报这种错误了: 浏览器抓包找到该请求,右键复制-->以cULR格式复制到https://spi
- 2022-07-26 19:02回答 1 已采纳 你都不先看下你发送到请求返回的值是什么嘛?就直接开始复制粘贴xpath那有这么简单
- 2021-11-27 19:16回答 2 已采纳 该页面数据是动态加载的,需要用此链接用post请求去获取https://www.xuetangx.com/api/v1/lms/get_product_list/?page=1
- 2018-11-17 23:45只剩渣了的博客 我有做过爬虫相关的工作,是每天都是重复着同样的工作——写爬虫的抓取规则,这时候我是使用的 是Xpath,而不是正则,事实是我在正常工作中(写爬虫的时候)也很少用到正则,并不是因为他不 好,而...
- 2022-02-22 13:40 Python爬虫 错误:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
json
python
有问必答
爬虫
回答 5 已采纳 async+await方法的url多了个斜杠,去掉就行了。要不多的那个斜杠接口出错返回的是html代码了,调用json()出错了,内容不是json字符串 测试代码如下 import json im
- 2023-04-04 00:31潜龙勿用丶的博客 python爬虫练习爬取音乐top250
- 2023-09-14 14:08青春不朽512的博客 在我们前面的文章中,我们探索了如何使用Scrapy库创建一个基础的爬虫,了解了如何使用选择器和Item提取数据,以及如何使用Pipelines处理数据。在本篇高级教程中,我们将深入探讨如何优化和调整Scrapy爬虫的性能,...
- 没有解决我的问题, 去提问

悬赏问题
- ¥15 这是哪个作者做的宝宝起名网站
- ¥60 版本过低apk如何修改可以兼容新的安卓系统
- ¥25 由IPR导致的DRIVER_POWER_STATE_FAILURE蓝屏
- ¥50 有数据,怎么建立模型求影响全要素生产率的因素
- ¥50 有数据,怎么用matlab求全要素生产率
- ¥15 TI的insta-spin例程
- ¥15 完成下列问题完成下列问题
- ¥15 C#算法问题, 不知道怎么处理这个数据的转换
- ¥15 YoloV5 第三方库的版本对照问题
- ¥15 请完成下列相关问题!