如题,尝试了很多方法但是还是不能删除,有没有大牛能想到是什么原因?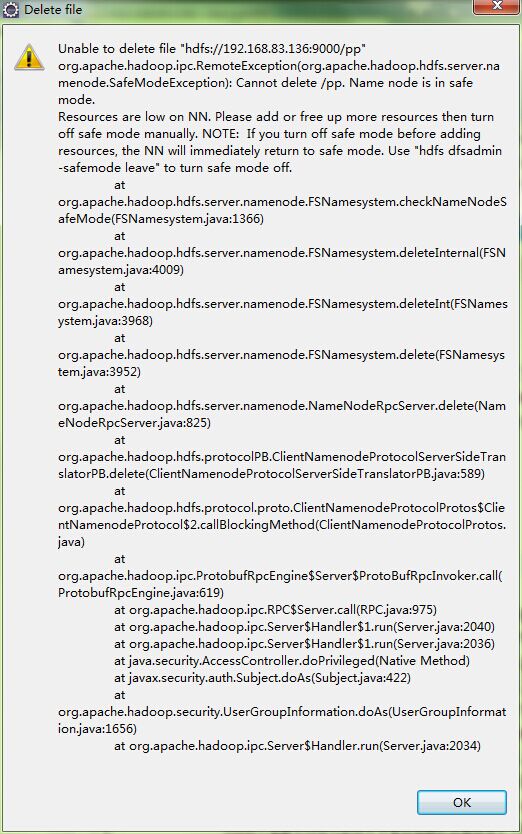

mapreduce编写失误产生大文件,但是无法删除,一直报在安全模式下,但是明明已经退出了。

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
- wangl66 2016-11-04 12:22关注
找到问题了,是因为磁盘占用率达到100%,导致的系统问题,不是集群的问题,将datanode上面的文件删除之后,恢复正常
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2020-12-22 23:16粉红猪๓的博客 目录 使用VirtualBox安装Ubuntu 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器,...在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示
- 2025-11-01 05:40蜜糖Py小兔的博客 本文提供了一份详细的Ubuntu系统下Hadoop单机部署实战指南。内容涵盖从创建专属用户、配置SSH免密登录、搭建Java环境,到完成Hadoop单机版安装与配置的全过程,并通过运行官方grep示例程序验证部署成功。本教程旨在...
- 2020-10-19 16:33okbin1991的博客 2.1 请随意使用各种类型的脚本语言实现:批量将指定目录下的所有文件中的$HADOOP_HOME$替换成 /home/ocetl/app/hadoop 2.2 假设有 10 台主机,H1 到 H10,在开启 SSH 互信的情况下,编写一个或多个脚本实现在所有的...
- 2017-03-27 10:52Together_CZ的博客 转自:http://blog.csdn.net/hguisu/article/details/7244798 转自:http://blog.csdn.net/hguisu/article/details/7244981 转自:... 本文转载了Google的三大核心技术,作为学习的记录需要的时候及
- 2024-12-17 10:29黄静雯•ᴗ•的博客 在生产环境中,Hadoop 通常采用完全分布式安装,即集群部署。Hadoop 具有典型的主从架构,HDFS 的 NameNode 是主节点,DataNode 是从节点;YARN 的 ResourceManager 是主节点,NodeManager 是从节点。在正式部署前,...
- xiaojiatian的博客 我们设计并实现了Google GFS文件系统,一个面向大规模数据密集型应用的、可伸缩的分布式文件系统。GFS虽然运行在廉价的普遍硬件设备上,但是它依然了提供灾难冗余的能力,为大量客户机提供了高性能的服务。 ...
- 2024-11-27 07:12大模型大数据攻城狮的博客 例如,在一些复杂的数据分析场景中,可先用 Hadoop 的 MapReduce 对原始数据进行初步的清洗和转换,将处理后的数据存储在 HDFS 中,然后再利用 Spark 的内存计算优势,快速地对这些数据进行进一步的分析和挖掘,如...
- 2023-05-03 23:19华尔街的幻觉的博客 Hadoop Distributed File System,简称HDFS,是一个Hadoop分布式文件系统。1)NameNode(老板):负责数据存在什么位置,整个数据的存储情况。2)DataNode:负责数据具体存在哪,存的什么信息。3)2NN(秘书):备份...
- 2025-06-09 03:21DIY飞跃计划的博客 软件包是IT行业中用于软件开发和分发...发布一个软件包到PyPI需要几个关键步骤,包括准备软件包元数据、编写setup.py文件、打包软件包以及上传到PyPI服务器。本章将简要介绍这些步骤,并为后续章节的深入讲解打下基础。
- 2011-12-12 11:27wh62592855的博客 随着人们对该些技术兴趣的上升,已经产生出一系列在它们之上进行编程的工具,而MapReduce就是其中最早也是最著名的一个。MapReduce非常具有吸引力,因为它提供了一种让用户可以编写相对复杂的分布式程序的简单模型,...
- 2023-04-28 16:53bmyyyyyy的博客 Flink 是一个分布式的流式数据的处理引擎,对于有界和无界数据进行状态计算,提供了很多便于用户编写分布式任务的 API,有 DataSetAPI,但是新版本中已经被舍弃了,即将淘汰了,现在用的是 DataStreamAPI,还有一些 ...
- 2024-10-18 16:10木马拾光的博客 (2)方案上,有很大的区别,MR的shuffle是基于合并排序的思想,在数据进入reduce端之前,都会进行sort,为了方便后续的reduce端的全局排序,而Spark的shuffle是可选择的聚合,特别是1.2之后,需要通过调用特定的...
- 2020-11-15 22:49ganshisheng的博客 系统建设目标 建设背景 监管背景 2016年12月30日颁布的《证券公司全面风险管理规范》要求当中,首次提出“证券公司应当建立健全数据治理和质量控制机制。...证券公司在金融市场上发挥着日益重要的作用,也面..
- 2025-07-08 18:38flyair_China的博客 抽样测试: 在大规模处理前,对数据子集进行清洗规则验证。 4.3 ETL增量优化的详细方案(海量数据场景的核心需求) 目标是只处理自上次运行以来发生变化的数据,避免全量处理的巨大开销。 精确...
- 2022-04-18 22:09张螂饿爬的博客 因为本人在学习Hadoop的时候,因为web端的yarn的resourcemanager无法连接,在试完网上那些解决方法后发现又把自己web端的HDFS给搞得连接不上了。 > 1. 主机可以ping各节点 > 2. 虚拟机可以ping外网 > 3. 防火墙以...
- 2021-09-20 23:18黑客&画家的博客 4.删除文件 del 5.打开计算机calc 6.打开画图mspaint 7.用echo "写入新数据">d:\a.txt,echo 字符串 >文件路径 文件名(会覆盖原内容) 8.用echo "写入新数据">>d:\a.txt,echo 字符串 >文件路径 ...
- 2017-08-09 11:41weixin_34390996的博客 高度移植语言JAVA的好处在于HDFS可以部署在大范围的机器上。典型的部署是,一台单独的机器部署Namenode,其他机器部署Datanode。 集群内部单个Namenode的存在极大地简化了系统体系。Namenode作为仲裁人,并且是...
- 2020-05-27 19:42Denovo丶的博客 线程安全问题:hashmap是非线程安全的,底层是一个Entry数组,put进来的数据,会计算其hash值,然后放到对应的bucket上去,当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的头...
- 2021-08-07 22:17crazy-6的博客 RabbitMq 几种工作模式 http://127.0.0.1:15672 guest/guest 消费模式 1、自动模式-消费者从消息队列获取消息后,服务端就认为该消息已经成功消费。 2、手动模式-消费者从消息队列获取消息后,服务端并没有标记为...
- 2022-03-27 14:13╭⌒若隐_RowYet——大数据的博客 2. 迟早老子会有钱,要买一台苹果Mac坐在星巴克追剧,那你会发现,Mac的命令行模式竟然和Linux惊人的相识,我每次用到Mac命令行操作都是直接网上直接copy的,不知道啥意思,这是我一个做设计的朋友跟我吐槽的,嘿嘿...
- 没有解决我的问题, 去提问
