首先我在Hbase中建了一张空表t1;
在hive中新建一张**外部分区表**使用HBaseStorageHandler与表t1映射起来;
hive中插入一条分区数据,hive中存在1条数据,Hbase中一条;
hive中插入第2,3,4,5条分区数据,**hive中存在25条数据,Hbase中5条**;why?
另外hive中select查询带第一个分区条件查询数据竟然显示全部数据??所以分区表和映射表同时使用无意义??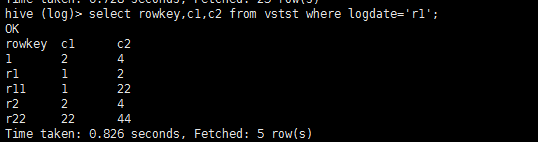

Hbase在hive中的映射表作为分区表查询障碍

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
- sccemstanford 2017-12-07 09:57关注
同问啊,我们现在遇到了一个类似场景,hbase中有需要用到的数据,但是另一个系统Kylin只能从hive中获取,为此,我准备Hbase中的表映射到hive中来,
如果这样Hive中就没办法分区了,以后数据量增大了,就不好弄了,如果我自己同步数据到hive中,就有两份数据,冗余了,伤脑经解决 无用评论 打赏举报 分享
- 2015-12-29 08:12回答 1 已采纳 http://bbs.csdn.net/topics/390911781
- 2022-11-18 18:05回答 3 已采纳 有可能多按按回车就好了,有的时候是卡了
- 2022-12-14 16:03回答 1 已采纳 hive和hbase都是大数据平台上的组件。hive类似于关系型数据库,按行存储,非常适合对sql比较熟悉的人按照sql语句进行数据处理。hbase属于非关系型数据库,采用列式存储,非常适合统计类的数
- 2022-12-27 15:36qq_35218261的博客 HBASE插入数据
- 2022-12-20 13:34
 关于#大数据#的问题:大数据实验Hive、M ySQL、HBase数据互导中,使用HBase J ava API把数据从本地导入到HBase中的ecli pse代码出问题要怎么解决吗
hadoop
hbase
大数据
回答 1 已采纳 编译报错?是不是跟JDK可能有关系
关于#大数据#的问题:大数据实验Hive、M ySQL、HBase数据互导中,使用HBase J ava API把数据从本地导入到HBase中的ecli pse代码出问题要怎么解决吗
hadoop
hbase
大数据
回答 1 已采纳 编译报错?是不是跟JDK可能有关系 - 2021-11-06 11:30 Hbase 和 hive 有什么区别?hive 与 hbase 的底层存储是什么?hive 是产生的原因是什么?habase 是为了弥补 hadoop 的什么缺陷?
hadoop
hbase
hive
有问必答
回答 1 已采纳 大数据之hadoop / hive / hbase 的区别是什么?有什么应用场景?_RunFromHere的博客-CSDN博客 文章目录1
- 2022-03-24 18:03回答 3 已采纳 所有字段都可以查询,如果需要处理可以使用ifnull转换,如: select ifnull(username,'替换值') from 表名
- 2020-12-29 19:28北京小小在香港的博客 Hive和HBase通过接口互通,用户可以方便地通过SQL接口进行建表、映射表、查询、删除等操作。由于对于hiveOnHbase表的查询走MR框架,因此查询效率较为缓慢需酌情使用。在非CM管理的CDH集群进行整合时需以下几步:1....
- 2022-04-21 01:37回答 2 已采纳 你在b站视频下面看看评论区,评论区下面的前几个有大佬提供了解决思路。我当时这里报错了,我用了评论区给的方法成功了。如果评论区的方法没有解决,说一个最不好听的方法,你把hive和spark重新装一遍。我
- 2021-12-09 10:28回答 1 已采纳 你这个表有多大,在数据量不大的情况下,肯定是传统的数据库快,spark还要一些启动过程啥。
- 2023-01-31 22:42回答 1 已采纳 有用请采纳,点击右侧采纳即可:取决于对数据的查询需求。如果需要跟踪每个业务操作的详细信息,则可以使用事务事实表。如果需要统计与离港信息相关的数据,则可以使用累积事实表。 在某些情况下,需要同时使用两种
- 2020-12-29 02:16李民伟的博客 @[toc]一、前言HBase 只提供了简单的基于 Key 值的快速查询...Hive 与 HBase 整合的实现是利用两者本身对外的 API 接口互相通信来完成的,其具体工作交由 Hive 的 lib 目录中的 hive-hbase-handler-xxx.jar 工具类...
- 2022-09-13 14:36回答 1 已采纳 该问题原因是因为各个服务器之间系统时间不同步导致的,linux系统时间同步请看这位博主https://blog.csdn.net/MaleLiu/article/details/106806284
- 2019-05-08 11:21刘李404not found的博客 一、准备 1.1 官方文档 https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration 1.2 依赖服务 Hive3.1.1:...Hbase2.1.0:https://blog.csdn.net/qq_396805...
- 2018-12-28 16:43花和尚也有春天的博客 Hbase表映射成hive中 一、1.Hive内部表,语句如下 1、hive中建表 CREATE TABLE member( m_id string , address_contry string , address_province string , address_city string , info_age string , info_...
- 没有解决我的问题, 去提问
