这个错误怎么修改呢?在网上找到一段代码,新手……找了半天资料还是不会修改错误,怎么改就能正常运行了……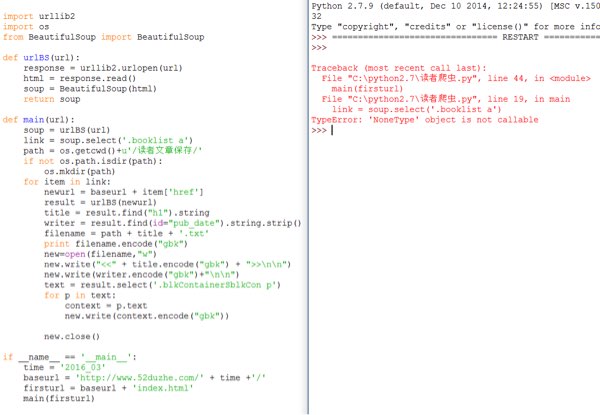

link = soup.select怎么用呢?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2021-03-05 12:57我不取名的博客 print soup.select('p #link1') #[] 直接子标签查找 print soup.select("head > title") #[ The Dormouse's story] (5)属性查找 查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,...
- 2020-12-08 21:38weixin_39915367的博客 #[] (4)组合查找 组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开 print soup.select('p #link1') #[] 直接子标签查找 ...
- 2020-08-11 17:56LFX今天发财了吗的博客 用webbrowser.open()函数打开网页 import webbrowser, sys, pyperclip if len(sys.argv)>1: content = sys.argv[1] else: content = pyperclip.paste() webbrowser.open(content) 打开cmd命令提示符,转换...
- 2019-10-07 22:56wei_lin的博客 soup.select()在源代码中的原型为: select(self, selector, namespaces=None, limit=None, **kwargs) 功能:查找html中我们所需要的内容 我们主要使用的参数是selector,其定义为”包含CSS选择器的字符串“。关于...
- 2020-12-08 21:39weixin_39636102的博客 本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家。具体如下:The Dormouse's storyThe Dormouse's storyOnce upon a time there were three little sisters; and their names were,Lacie ...
- 2020-12-08 21:39weixin_39541693的博客 总结评论:选择查找多个实例并返回一个列表,查找查找第一个实例,因此它们不会执行相同的操作。...就灵活性而言,我认为您知道答案,soup.select("div[id=foo] > div > div > div[cla...
- 2018-11-12 18:04XTY00的博客 print soup.select('#link1') #[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie -->] (4)组合查找 组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,...
- 2020-08-14 11:42LFX今天发财了吗的博客 1、用select()方法整理 import bs4, requests file_object = open('F:\\python_work\\CSDN\\douban.html', 'rb') #以二进制形式打开文件 soup = bs4.BeautifulSoup(file_object, features='html.parser') linkTitle...
- 2022-10-04 16:12the丶only的博客 Python 爬虫正则表达式和re库在爬虫过程中,可以利用正则表达式去提取信息,但是有些人...这时候可以用高效的网页解析库Beautiful Soup。Beautiful Soup 是一个HTML/XML 的解析器,主要用于解析和提取 HTML/XML 数据。
- 2024-04-25 21:12乐队1的博客 BeautifulSoup 是一个用于解析HTML和XML文档的Python库。它提供了一种灵活和便捷的方式来导航、搜索和修改解析树。BeautifulSoup简化了网络爬虫的工作,使得开发者可以轻松地解析网页内容,提取所需的数据。
- 2023-10-16 16:18markvivv的博客 网页抓取是指从网站上自动提取数据。这包括访问网页,检索网页内容,并使用脚本或工具从网页的 HTML 结构中提取特定数据。...收集到的信息可以有组织的格式保存,如数据库或 CSV 文件,以供日后研究或使用。
- 2020-03-25 23:19cuicui_ruirui的博客 90%的数据不在我们的数据库里,散落在网络世界,以网页资料形式呈现,即为非结构化数据,他们没有固定的数据格式,必须通过ETL(Extract,Transformation,Loading)工具将数据转化为结构化数据才能取用 二、ETL E...
- 没有解决我的问题, 去提问
