关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
一个治疗术
2016-11-30 09:43
采纳率: 50%
浏览 994
首页
已结题
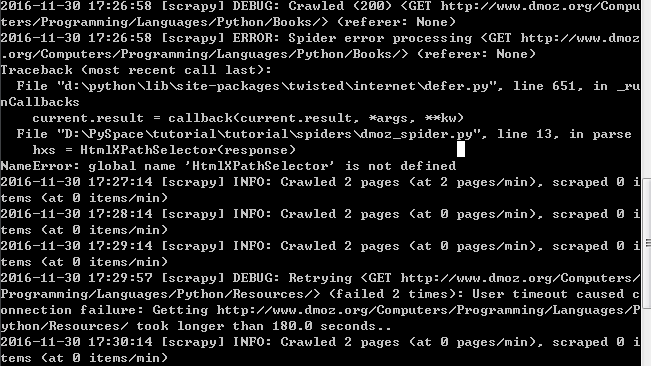
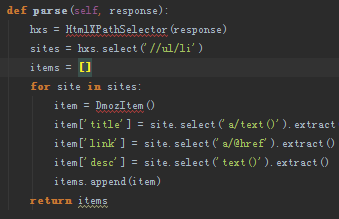
scrapy xpth (入坑求教)
NameError: global name 'HtmlXPathSelector' is not defined
这是为什么
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
oyljerry
2016-11-30 12:13
关注
你这个函数有没有定义?如何实现的
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
Scrapy
入门篇
2024-08-05 10:37
沐曦可期的博客
本文用于记录
scrapy
的基础知识点,适合入门学习和复习
Scrapy
网络爬虫框架学习
2025-09-13 21:16
YoungLime的博客
Scrapy
是一个用Python编写的开源爬虫框架,目标是帮助开发者高效地从网站上提取数据。它和单纯用 requests + BeautifulSoup 不一样,
Scrapy
提供了一整套完整的“爬虫解决方案”,非常适合做中大型爬虫项目。
scrapy
框架
2024-09-28 22:01
Justinc.的博客
组件作用
Scrapy
Engine(引擎)负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等已实现Scheduler(调度器)它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当...
Scrapy
项目创建
2024-10-22 10:30
smile8421的博客
Scrapy
项目创建
Scrapy
爬虫框架介绍
2024-08-05 20:06
7 号的博客
Scrapy
是什么、创建
Scrapy
项目、配置请求头、配置管道、数据建模
Python-
Scrapy
库详解
2025-03-20 08:59
wanglaqqqq的博客
Scrapy
是 Python 生态中 。
Scrapy
爬虫框架全解析
2024-12-12 22:37
狂宠粉博主的博客
基本定义
Scrapy
是一个用 Python 编写的开源网络爬虫框架。它旨在快速、高效地抓取网页数据,可处理大规模的数据抓取任务。基于 Twisted 异步网络库构建,能够并发地处理多个请求,大大提高了数据抓取的速度。遵循 ...
爬虫框架:
Scrapy
介绍
2025-02-06 15:14
薛定谔的脂肪层的博客
Scrapy
是一个为了爬取网站数据,提取结构性数据而编写的应用框架。其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所...
分布式爬虫之
Scrapy
2024-04-20 09:20
Cherry Xie的博客
官方文档](https://docs.
scrapy
.org/en/latest/topics/item-pipeline.html)
爬虫框架快速入门——
Scrapy
2024-11-30 20:51
drebander的博客
Scrapy
是一个基于 Python 的网络爬虫框架,它能帮助你快速爬取网站上的数据,并将数据保存到文件或数据库中。
Scrapy
对静态页面支持很好,但对动态加载的内容可能无效。通过
Scrapy
,你可以轻松爬取各种网站的数据...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享


