
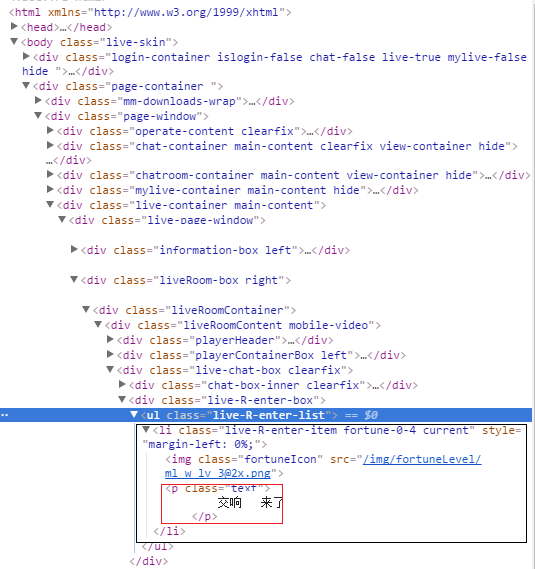
学习webdriver挺有趣的,给自己找了个练习。
我想取截图红框里 ”交响来了“这几个字。
我这样写的
driver.find_elements_by_css_selector('body > div.page-container > div.page-window > div.live-container.main-content > div > div.liveRoom-box.right > div.liveRoomContainer > div > div.live-chat-box.clearfix > div.live-R-enter-box > ul > li > p')
可取到的结果是
[]
是为什么?
(黑框里的内容是动态添加的)




