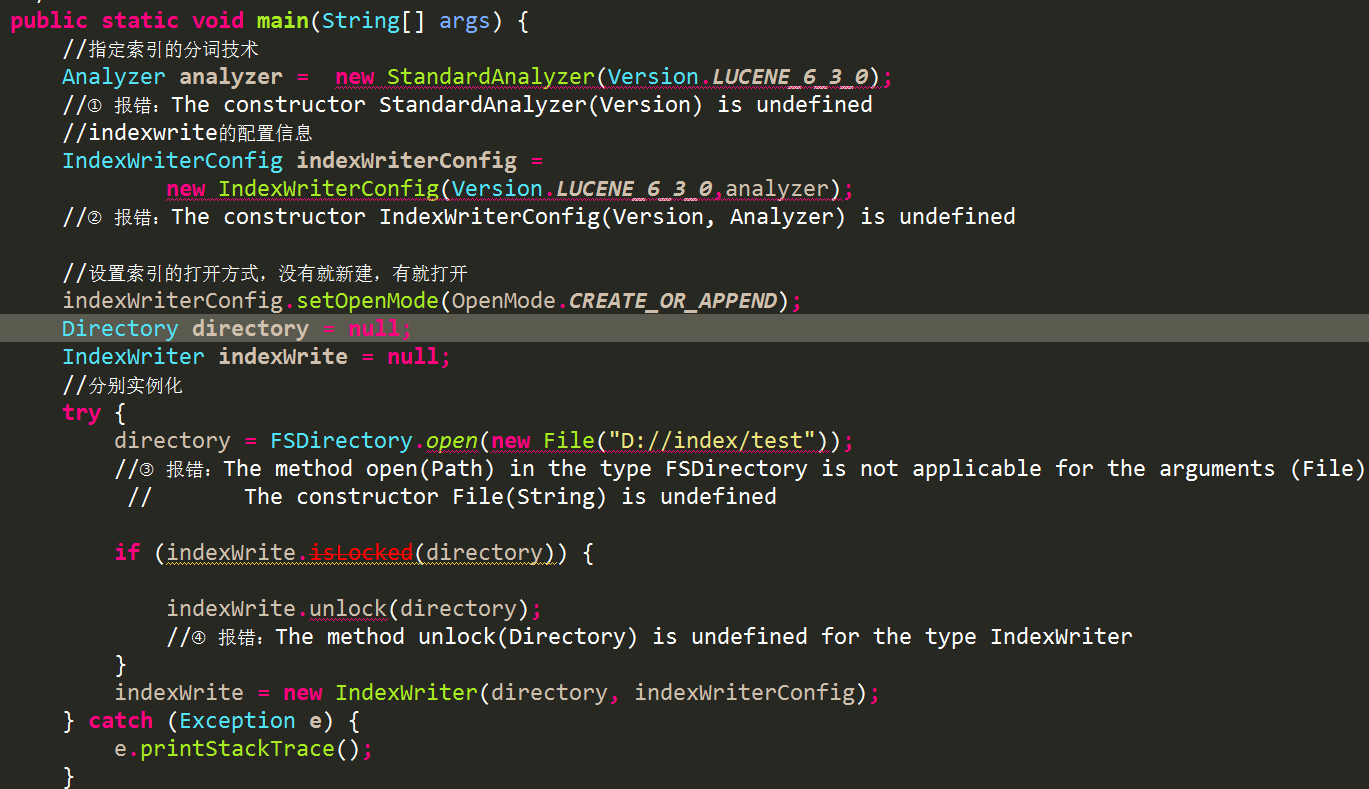

新手lucene求助,创建索引遇到问题,配置与报错信息如图所示,真心求解

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 Little_Cigar 2017-12-06 06:40关注
Little_Cigar 2017-12-06 06:40关注用这种方法啊,Directory directory = FSDirectory.open(Paths.get(indexPath)); indexPath是你的D://index/test
解决 无用评论 打赏举报 分享
- 2025-06-10 13:31内容概要:本文档是关于智能搜索技术课程中“倒排索引创建”的实验报告。主要内容分为两大部分:第一部分是构造倒排索引,通过对给定的四个文档进行处理,提取关键词并构建倒排索引结构,同时介绍了如何使用jieba...
- 2026-01-10 14:57报告详细阐述了Lucene的倒排索引机制、分词处理、索引创建与检索查询的工作流程,并通过代码示例展示了索引构建和关键词搜索的具体实现。同时,文章说明了Lucene的多语言适配性、灵活扩展架构及其在Elasticsearch、...
- 2021-08-18 12:19贵沫末的博客 一、创建索引 package com.gykalc.rediscluster.lucene.index; import com.gykalc.rediscluster.lucene.ikanalyzer.IKAnalyzer6x; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.document...
- 2011-06-14 14:35### Lucene3.0创建索引 在Lucene3.0中创建索引是一个关键功能,可以帮助用户快速地检索和管理大量的文本数据。本篇文章将详细介绍如何使用Lucene3.0来创建索引,并通过一个具体的例子来演示整个过程。 #### 一、...
- 2017-11-20 10:39Lucene创建索引步骤: 1、创建Directory(索引位置) 2、创建IndexWrite(写入索引) 3、创建Document对象 4、为Document添加Field(相当于添加属性:类似于表与字段的关系) 5、通过IndexWriter添加文档到索引中
- 2022-01-24 13:49程序员资料站的博客 Lucene是一个高性能、可伸缩的信息搜索(IR)库。 Information Retrieval (IR) library.它可以为你的应用程序添加索引和搜索能力。 Lucene是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文...
- 2015-10-18 15:46### Lucene创建与搜索索引 #### 一、Lucene简介 Lucene是Apache软件基金会下的一个开源全文搜索引擎工具包,由Java编写而成。它提供了一整套完整的文本索引和搜索机制,包括分词、索引、搜索等功能,并且性能高效...
- 2017-06-20 10:58java创建Lucene索引
- 2026-01-13 02:04基于Lucene的中文搜索引擎构建实验项目_网页预处理与索引创建_实现高效信息检索与查询功能_使用ICTCLAS分词和IKAnalyzer工具_支持分页显示与结果高亮_适用于Web.zip网络
- 2020-12-30 18:39嵌入式随笔的博客 从问题出发,这篇内容可以解决以下几个问题:一:如何开启关闭Es索引(数据库)?二:如何创建索引(数据库)结构?三:如何向已有索引(数据库)中添加类型(表)结构?四:如何向已有类型(表)中添加新字段?五:如何更改...
- 没有解决我的问题, 去提问

