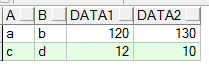
a和b列颠倒后,去除重复数据后效果
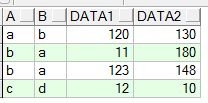
select 'a' a, 'b' b, 120 data1, 130 data2 from dual
union all
select 'b' a, 'a' b, 11 data1, 180 data2 from dual
union all
select 'b' a, 'a' b, 123 data1, 148 data2 from dual
union all
select 'c' a, 'd' b, 12 data1, 10 data2 from dual
a和b列颠倒后,去除重复数据后效果