写了个简单的socket通讯的小程序,但是传入中文的时候输出一直是乱码,在网上看了资料得知是因为一次读一个byte,但是中文是两个byte导致每次读一半出错的。
求各大神指点。下面放上代码:
TCPSERVER服务端:
class TCPServer{
public static void main(String[] args)throws IOException{
ServerSocket listen = new ServerSocket(5050);
Socket server = listen.accept();
InputStream in = server.getInputStream();
OutputStream out = server.getOutputStream();
StringBuffer sb=new StringBuffer();
int c;
for(int i=0;i<20;i++)
{
sb.append((char)(c=in.read()));
}
System.out.println("sb="+sb);
MessageRule message=new MessageRule();
message.unpack(sb);
if(message.getPrcsd().equals("2101"))
{
String s=new String(message.getBody(),"iso8859_1");
System.out.println("s:"+s);
}
System.out.println("server收到:" + sb);
out.write(message.getBody());
out.close();
in.close();
server.close();
listen.close();
}
}
TCPCLIENT客户端
class TCPClient{
public static void main(String[] args)throws IOException{
Socket client = new Socket("127.0.0.1" , 5050);
InputStream in = client.getInputStream();
OutputStream out = client.getOutputStream();
Filewriter file = new Filewriter();
MessageRule message=new MessageRule();
byte[] sendBye=message.pack("I'm 客户端!","2101");
StringBuffer sbclient=new StringBuffer();
out.write(sendBye);
char c ;
for(int i=0;i<8;i++)
{
sbclient.append((char)(c=(char) in.read()));
}
System.out.println("client收到:" + sbclient);
out.close();
in.close();
client.close();
}
}
下面是中间涉及的pack方法:
public byte[] pack(String body,String prcsd)
{
length=prcsd.length()+body.length();
String str = String.format("%08d", length);
String sTotal=str+prcsd+body;
System.out.println("sTotal="+sTotal);
try
{
return sTotal.getBytes("iso8859_1");
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
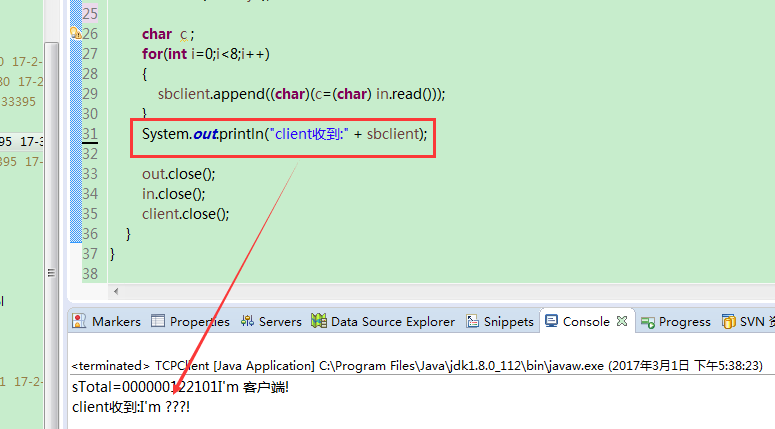
结果如下,中文是乱码