关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
lewis@110
2017-03-09 05:54
采纳率: 0%
浏览 3717
首页
Python
已结题
python requests.get(url) 采集网页中文乱码问题。
python
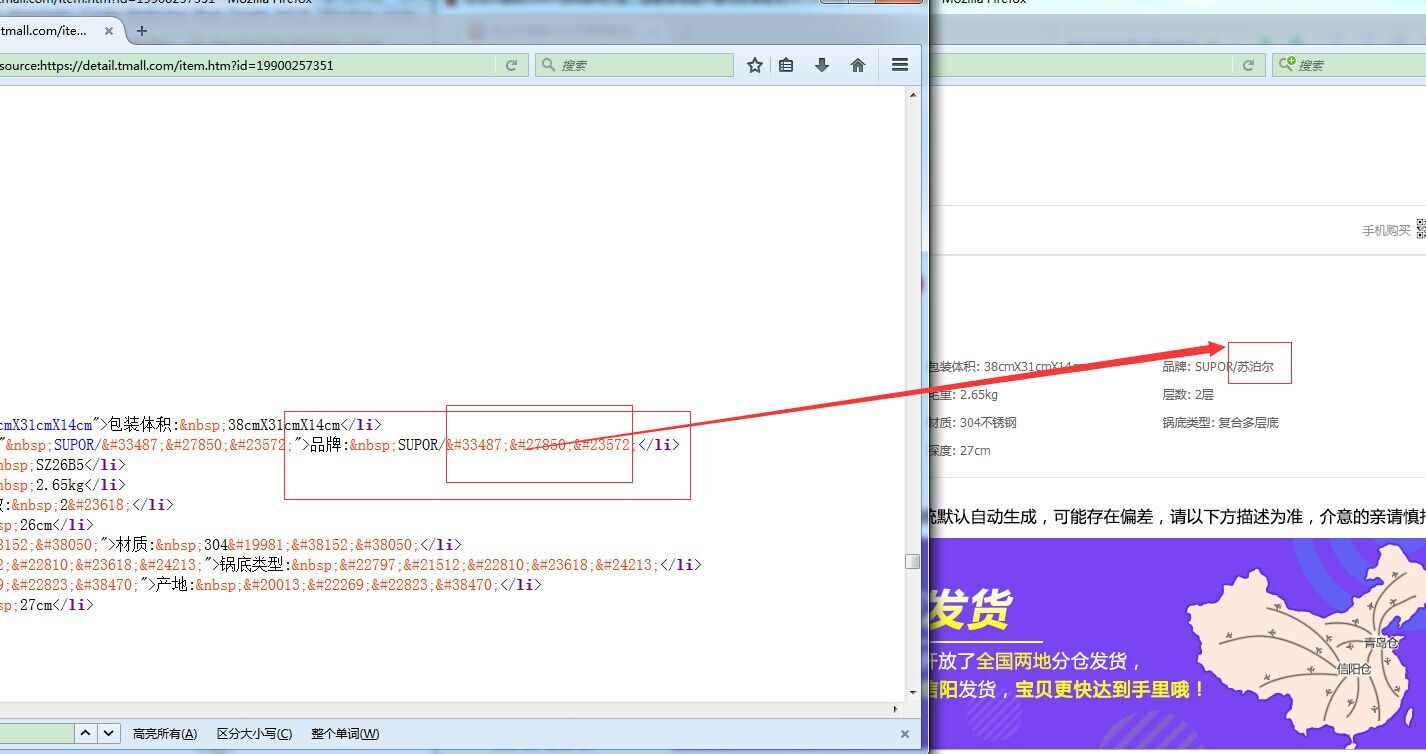
如图:这个编码怎么解决,
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
6
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
student-ai
2017-03-09 06:00
关注
看下编码是不是gbk,设置一下编码,
http://cn.python-requests.org/zh_CN/latest/
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(5条)
向“C知道”追问
报告相同问题?
提交
关注问题
python
中
requests
.get()乱码
问题
2023-04-05 20:17
m0_58370843的博客
问题
: 出现编码
问题
错误。 解决方法:(//后面没有用上) import sys import io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') 后出现这个情况 继续乱码 print(rep.encoding) # 查看 发现我...
python
爬虫
requests
.get()出现乱码
问题
2021-10-27 08:25
叫Lzy的博客
response=
requests
.get(
url
) print(response.text) 上面是一般的爬虫方法,这样可能会出现乱码
问题
那么如何解决呢,很简单,只需要加入一行 response.encoding = response.apparent_encoding 正确代码如下 ...
python
request.get乱码_
python
requests
乱码解决方案(转)
2020-12-24 20:45
李旭海的博客
python
requests
乱码解决方案(转)版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/getcomputerstyle/article/details/71194418在使用...
记一次
requests
.get()返回数据乱码
问题
2024-05-13 07:18
liangblog的博客
搜索发现:造成乱码除了编码格式方面外,另外还有可能是因为压缩格式导致的。在请求头中,‘Accept-Encoding’是浏览器发给服务器,声明浏览器支持的编码类,一般有gzip,deflate,br 等等。很多网站都是以gzip的格式...
解决
python
3中的
requests
解析中文页面出现乱码
问题
2020-09-19 11:13
总的来说,解决
requests
在
Python
3中解析中文页面出现乱码
问题
的关键在于正确设置`response.encoding`属性。在实际开发中,应对不同编码的
网页
有充分的认识,合理处理编码
问题
,确保数据的正确解析。在编写爬虫或...
Python
新手入门:用
requests
.get()打开
url
2022-10-16 11:24
SY_4547的博客
说明 res 是
requests
.models模块里面名为Response的实体化,通过 res =
requests
.get(
url
, headers= headers )实现,这边等式的左边在编写时res可换换成任何变量名称,调用时根据实体化的变量名称调用就是,通用...
Python
requests
.get()方法详解[项目源码]
2025-11-13 07:59
在
Python
的网络请求库
requests
中,get()方法是一个非常基础且常用的方法,用于发送HTTP GET请求到指定的
URL
,并返回一个响应对象Response。这篇文章详细讲解了get()方法的各个方面,包括其基本的用法和参数的详细...
python
3 爬虫相关学习3:response=
requests
.get(
url
)的各种属性
2023-05-15 21:04
奔跑的犀牛先生的博客
中文GBK,英文ASCII ,繁体中文big5。共收录了21003个汉字,883个字符。编码范围是0x8140~0xFEFE。utf-8编码带BOM 和 无BOM的。(1个字节是8位2进制)utf-8 兼容 ascii。(2个字节是16位)标准ascii 字符集。扩展ascii ...
python
中
requests
爬去
网页
内容出现乱码
问题
解决方法介绍
2020-12-25 08:45
最近在学习
python
爬虫,使用
requests
的时候遇到了不少的
问题
,比如说在
requests
中如何使用cookies进行登录验证,这可以查看这篇文章。这篇博客要解决的
问题
是如何避免在使用
requests
的时候出现乱码。 import ...
python
爬虫
requests
get_
python
-爬虫-
requests
.get()-响应内容
中文乱码
2020-11-23 23:07
weixin_39630182的博客
python
-爬虫-
requests
.get()-响应内容
中文乱码
由于目标
url
的headers没有提供charset,那么这串字节流就会用latin-1 转换为 unicode 编码的方式转换成了我们见到的unicode对象。但是
网页
的编码方式实际上是utf-8,...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享



