
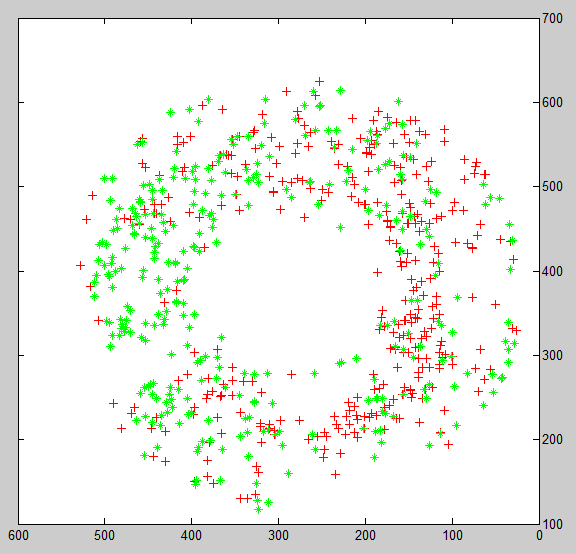
如图1,是我打算进行分类的样本点,标签已经用点的颜色进行表示,很明显能够看出来左侧主要为绿色点,右侧主要为红色点,直观上看决策线应该是一条竖直的直线
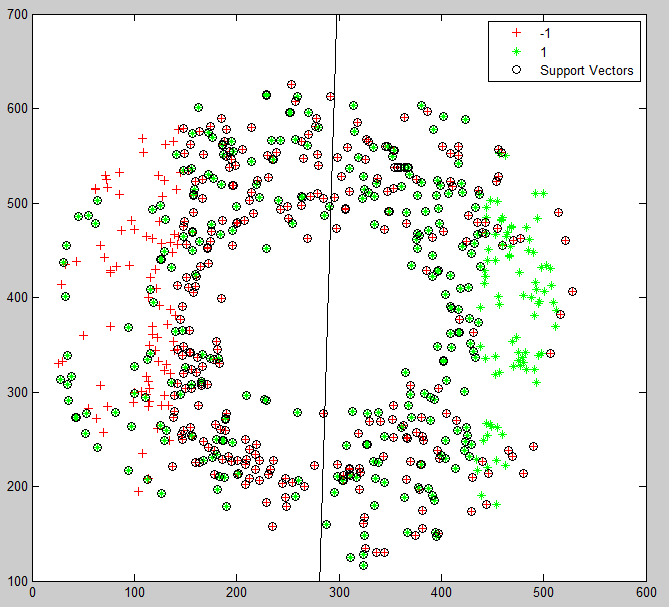
图2是我利用MATLAB里自带的svmtrain函数进行的分类结果,可以发现决策边界与理论上的竖直直线近似。
但我发现了一个重大的问题,图像中用黑色圆圈圈出来的点是支持向量,而这些支持向量基本把错误点全部圈出来了(即绿色分类里的红色点,红色分类里的绿色点,全部都是支持向量)
请问这种现象是为什么?可以从原理上去解释这个问题吗?
请求高人指点,十万火急!
PS:图2和图1相比,我做了一下轴对称,图1中绿色类在左边,图2中在右边,这个不影响最终结果






