有个网址是动态的,我需要爬取的数据存储在json数据格式中,
这个用json模块读取没毛病,
但是存在这么一个问题,就是向这个数据url提交访问请求时,
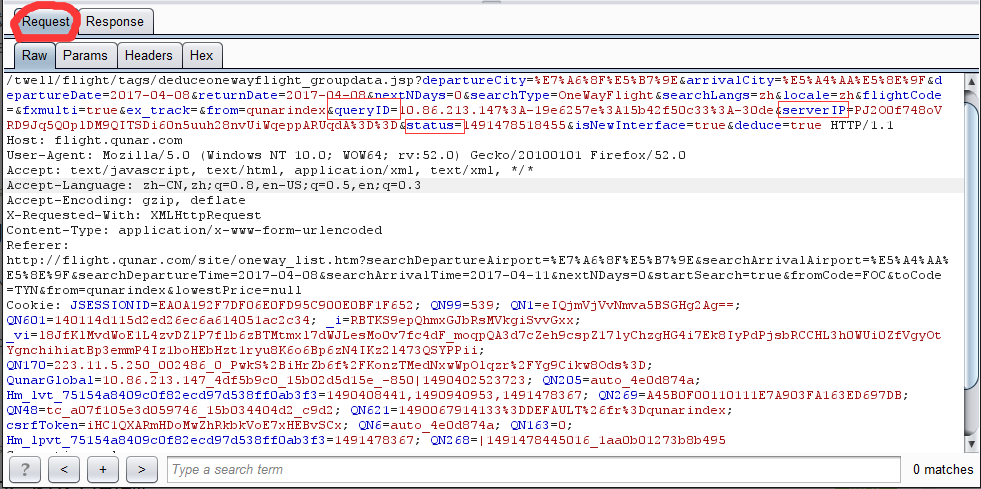
有加密的参数,比如queryID,serverIP,status这三个参数,删去这几个参数去访问是被对方服务器禁止的,
而且通过正常浏览器访问的话,这个页面会在一分钟左右失效不可访问
去找cookies,没在cookies中找到与这三个参数有关联,我没法构造出这个数据页面的url
想问问各位大牛,向某个网站请求的时候,这些动态的参数一般会存储在哪里?怎么获取这种动态添加的参数?
感激不尽!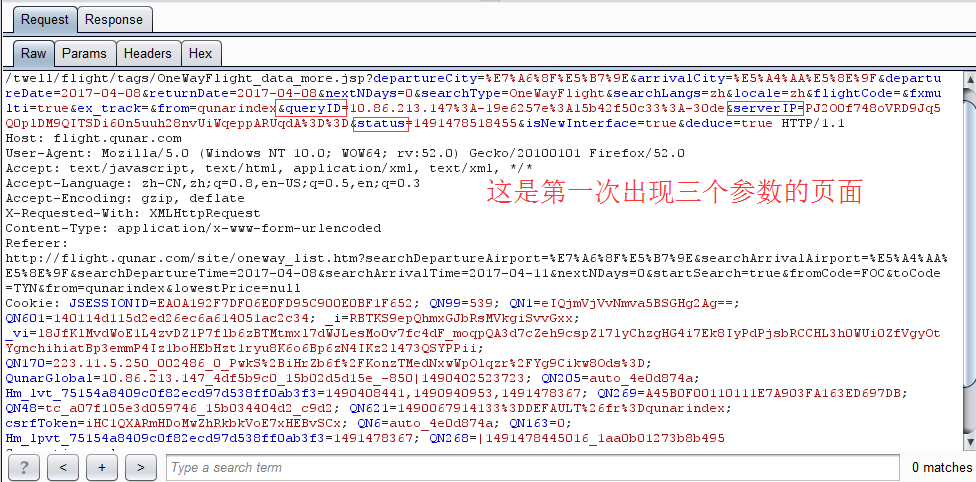

python爬取动态网址时如何获取发送的参数

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 oyljerry 2017-04-06 14:39关注
oyljerry 2017-04-06 14:39关注可以用selenium等webdriver来加载页面访问。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2023-07-26 13:21需要注意的是,使用Python爬取淘宝商品价格时,应该遵循以下几点: 遵守相关网站的使用规定和政策,尊重网站的隐私和版权。 使用合适的请求头信息,模拟浏览器行为,避免被网站防爬机制识别为爬虫。 处理网页解析的...
- 2022-04-11 09:09夜阑雨_的博客 爬取静态的数据很简单,爬取动态的数据就有一点麻烦了。 问题描述 提示:这里描述项目中遇到的问题: 比如说我们在爬取这个网页的时候 打开开发者工具可以看到点击量可以显示 但是我们爬取来的内容确是这个样子的...
- 2021-11-10 15:49总结起来,"python爬取携程网评论.zip"项目涵盖了Python网络爬虫的基本流程:发送HTTP请求获取网页,解析HTML提取所需信息,处理分页,数据清洗与存储。这个过程既锻炼了Python编程技能,也提升了数据分析的能力,是...
- 2023-04-02 19:11在这个场景中,我们将学习如何使用Python来爬取招聘网站上的职位信息,并将其存储为CSV文件。以猎聘网为例,我们将介绍以下关键知识点: 1. **Parsel库**: Parsel是基于XPath和CSS选择器的Python库,用于从HTML或...
- 2023-07-26 10:39要使用Python爬取药品信息,可以按照以下步骤进行: 导入相关库:首先需要导入必要的Python库,如requests(用于发送HTTP请求)、BeautifulSoup(用于解析HTML内容)等。 发送请求:使用requests库的get()方法发送...
- 2025-08-22 12:00使用Python爬取链家网站的示例代码,不仅可以帮助我们收集到丰富的房地产市场数据,而且通过实际操作,我们可以学习到网络爬虫技术在实际应用中的具体实现方法,并能够通过数据分析对市场趋势做出一定的预测和判断。...
- 2020-09-21 04:48下面是一个具体的例子,展示了如何使用Python爬取Bitbucket这样的需要登录的网站: ```python import requests from lxml import html # 创建session对象。这个对象会保存所有的登录会话请求。 session_requests =...
- 2025-11-13 07:15接着,通过编写Python代码,利用requests库发送HTTP请求,获取文档的操作ID(operationId),并通过轮询检查导出进度,最终下载Excel文件。文章强调了合理、安全地使用网络爬虫的重要性,并提供了完整的代码示例,...
- 2020-09-16 09:27通过使用Python中的`requests`库发送请求,结合`json`库解析返回的JSON格式数据,可以有效地获取所需的动态数据。需要注意的是,不同的网站可能会有不同的请求方式和数据格式,因此实际操作中可能还需要进一步调试和...
- 2017-12-27 16:32在爬取京东手机参数时,我们首先要做的就是向京东的商品页面发送GET请求,获取HTML页面内容。这可以通过requests.get()函数实现,同时可能需要设置headers以模拟浏览器行为,避免被网站识别为机器人。 接下来,我们...
- 没有解决我的问题, 去提问

