
这里显示错误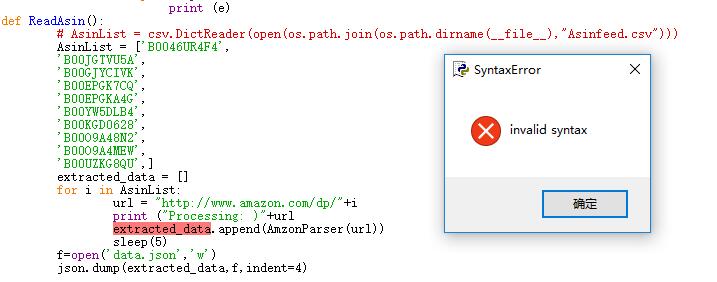
from lxml import html
import csv,os,json
import requests
from exceptions import ValueError
from time import sleep
def AmzonParser(url):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'}
page = requests.get(url,headers=headers)
while True:
sleep(3)
try:
doc = html.fromstring(page.content)
XPATH_NAME = '//h1[@id="title"]//text()'
XPATH_SALE_PRICE = '//span[contains(@id,"ourprice") or contains(@id,"saleprice")]/text()'
XPATH_ORIGINAL_PRICE = '//td[contains(text(),"List Price") or contains(text(),"M.R.P") or contains(text(),"Price")]/following-sibling::td/text()'
XPATH_CATEGORY = '//a[@class="a-link-normal a-color-tertiary"]//text()'
XPATH_AVAILABILITY = '//div[@id="availability"]//text()'
RAW_NAME = doc.xpath(XPATH_NAME)
RAW_SALE_PRICE = doc.xpath(XPATH_SALE_PRICE)
RAW_CATEGORY = doc.xpath(XPATH_CATEGORY)
RAW_ORIGINAL_PRICE = doc.xpath(XPATH_ORIGINAL_PRICE)
RAw_AVAILABILITY = doc.xpath(XPATH_AVAILABILITY)
NAME = ' '.join(''.join(RAW_NAME).split()) if RAW_NAME else None
SALE_PRICE = ' '.join(''.join(RAW_SALE_PRICE).split()).strip() if RAW_SALE_PRICE else None
CATEGORY = ' > '.join([i.strip() for i in RAW_CATEGORY]) if RAW_CATEGORY else None
ORIGINAL_PRICE = ''.join(RAW_ORIGINAL_PRICE).strip() if RAW_ORIGINAL_PRICE else None
AVAILABILITY = ''.join(RAw_AVAILABILITY).strip() if RAw_AVAILABILITY else None
if not ORIGINAL_PRICE:
ORIGINAL_PRICE = SALE_PRICE
if page.status_code!=200:
raise ValueError('captha')
data = {
'NAME':NAME,
'SALE_PRICE':SALE_PRICE,
'CATEGORY':CATEGORY,
'ORIGINAL_PRICE':ORIGINAL_PRICE,
'AVAILABILITY':AVAILABILITY,
'URL':url,
}
return data
except Exception as e:
print (e)
def ReadAsin():
# AsinList = csv.DictReader(open(os.path.join(os.path.dirname(__file__),"Asinfeed.csv")))
AsinList = ['B0046UR4F4',
'B00JGTVU5A',
'B00GJYCIVK',
'B00EPGK7CQ',
'B00EPGKA4G',
'B00YW5DLB4',
'B00KGD0628',
'B00O9A48N2',
'B00O9A4MEW',
'B00UZKG8QU',]
extracted_data = []
for i in AsinList:
url = "http://www.amazon.com/dp/"+i
print ("Processing: )"+url
extracted_data.append(AmzonParser(url))
sleep(5)
f=open('data.json','w')
json.dump(extracted_data,f,indent=4)
if __name__ == "__main__":
ReadAsin()



