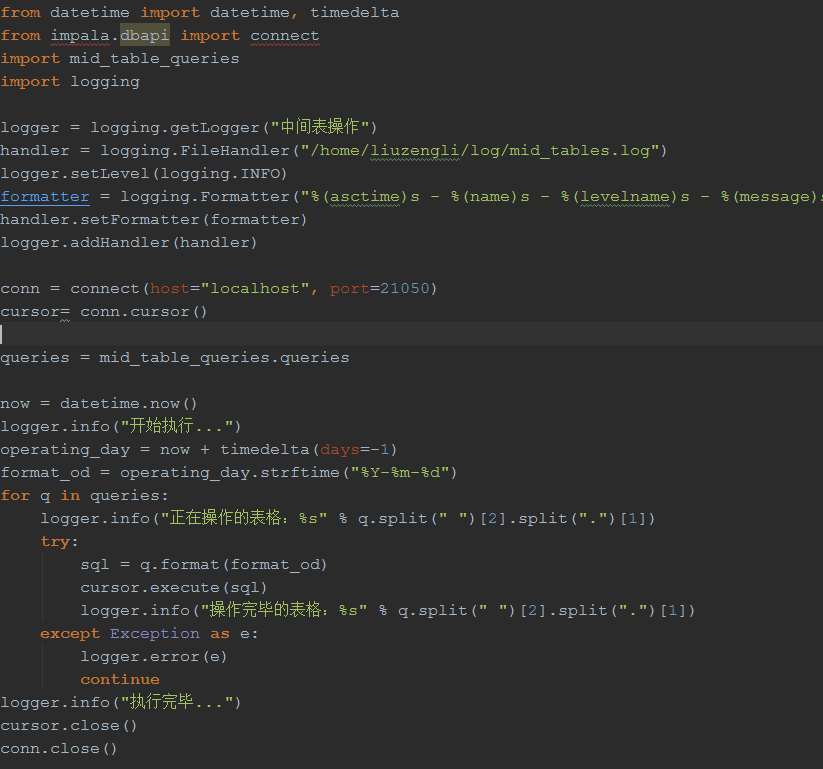
这是什么原因呀!ip没有错
Traceback (most recent call last):
File "mid_tables.py", line 17, in
cursor= conn.cursor()
File "/usr/lib/python2.6/site-packages/impala/hiveserver2.py", line 125, in cursor
session = self.service.open_session(user, configuration)
File "/usr/lib/python2.6/site-packages/impala/hiveserver2.py", line 995, in open_session
resp = self._rpc('OpenSession', req)
File "/usr/lib/python2.6/site-packages/impala/hiveserver2.py", line 923, in rpc
response = self._execute(func_name, request)
File "/usr/lib/python2.6/site-packages/impala/hiveserver2.py", line 940, in _execute
return func(request)
File "/usr/lib/python2.6/site-packages/impala/_thrift_gen/TCLIService/TCLIService.py", line 175, in OpenSession
return self.recv_OpenSession()
File "/usr/lib/python2.6/site-packages/impala/_thrift_gen/TCLIService/TCLIService.py", line 193, in recv_OpenSession
result.read(self._iprot)
File "/usr/lib/python2.6/site-packages/impala/_thrift_gen/TCLIService/TCLIService.py", line 1109, in read
fastbinary.decode_binary(self, iprot.trans, (self._class__, self.thrift_spec))
AttributeError: 'TBufferedTransport' object has no attribute 'trans'