
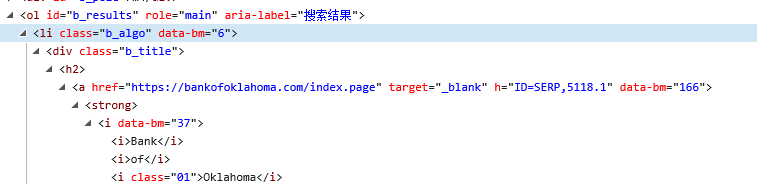
我想要解析出图中的链接,通过先识别 li 定位。可是查看soup的文本,所有data-* 都没有解析出来
代码如下
keywords = input('输入关键词PLZ')
res = requests.get('https://www.bing.com/search?q='+str(keywords)+'&qs=n&form=QBLH&scope=web&sp=-1&pq=abc&sc=8-5&sk=&cvid=3FE7B447AE744DD1AF25B5919EE1B675')
try:
res.raise_for_status()
except Exception as ecp:
print('There is an Exception:',ecp)
soup = bs4.BeautifulSoup(res.text,'html.parser')
ol = soup.find('ol',id='b_results')
linkElement = soup.find_all(attrs={'data-bm':'7'})
结果linkElement为空






