
假设这是我爬取的页面:http://www.rosiyy.com/xiaoyan/rosi1559.html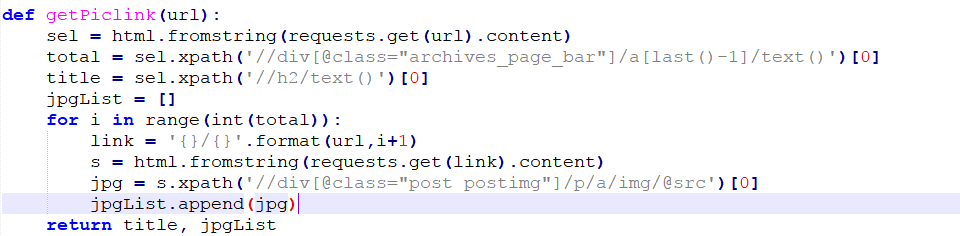
但是要爬取的页面有多个图片,求大神有什么思路?
以下是我的全部代码
# coding:utf-8
import requests
from lxml import html
import os
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def getPage(pageNum):
baseUrl = 'http://www.rosiyy.com/tag/%E8%82%89%E4%B8%9D-5.html'.format(pageNum)
selector = html.fromstring(requests.get(baseUrl).content)
urls = []
for i in selector.xpath('//div[@class="photo"]/a/@href'):
urls.append(i)
return urls
def getPiclink(url):
sel = html.fromstring(requests.get(url).content)
total = sel.xpath('//div[@class="archives_page_bar"]/a[last()-1]/text()')[0]
title = sel.xpath('//h2/text()')[0]
jpgList = []
for i in range(int(total)):
link = '{}/{}'.format(url,i+1)
s = html.fromstring(requests.get(link).content)
jpg = s.xpath('//div[@class="post postimg"]/p/a/img/@src')[0]
jpgList.append(jpg)
return title, jpgList
def downloadPic((title, piclist)):
k = 1
count = len(piclist)
dirName = u"【%sP】 %s" %(str(count), title)
os.mkdir(dirName)
for i in piclist:
filename = '%s/%s/%s.jpg' %(os.path.abspath('.'), dirName, k)
print u'Download:%s 第%s张' %(dirName, k)
with open(filename, "wb") as jpg:
jpg.write(requests.get(i).content)
time.sleep(0.5)
k += 1
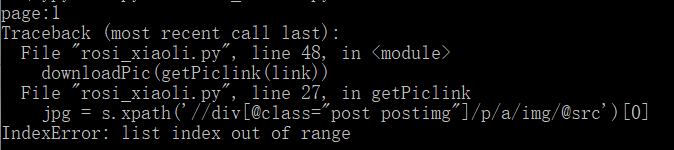
if __name__ == '__main__':
pageNum = input(u'page:')
for link in getPage(pageNum):
downloadPic(getPiclink(link))







