利用 Java代码 怎么实现基于solr的HBase的多条件查询,
即:对索引字段的过滤查询,和对索引字段的查询

solr API 如何实现过滤查询和索引字段的查询

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 chenjiexixi 2017-06-19 07:50关注
chenjiexixi 2017-06-19 07:50关注看下这篇博客,你要的功能在博客下面点
http://www.cnblogs.com/chenz/articles/3229997.html解决 无用评论 打赏举报 分享
- 2021-12-07 11:51回答 1 已采纳 {!join fromIndex=B from=id to id}name:qiwu AND age:[20 TO *] ,注意AND要大写!如果要加A表的条件,则要把{!join fromIndex
- 2017-05-15 06:26回答 2 已采纳 # facet=on&facet.range=fetchTime&facet.range.start=2017-03-01T00:00:00Z&facet.range.end=2017-05-16T2
- 2017-03-23 07:38回答 1 已采纳 http://blog.csdn.net/zhushuai1221/article/details/51740846
- 2014-10-09 13:47zachary_OOM的博客 HBase目前只支持对rowkey的一级索引,对于二级索引还不支持,当然可以把所有要索引的字段都拼接到rowkey中,根据hbase的filter功能进行查询,但是这样操作数据会涉及到全表扫描,效率很低,速度慢,不利于后期扩展。...
- 2015-05-02 12:23回答 2 已采纳 make sure the fields have stored=true <field name="field_name" type="text_general" indexed="tr
- 2016-07-08 02:20回答 1 已采纳 用fq试一下吧 fq={!frange l=100 u=1000}sum(x,y) 有用就请采纳吧!
- 2017-04-24 06:23回答 1 已采纳 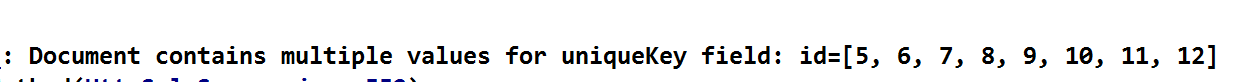报的这种错
- 2020-11-22 01:36weixin_39983383的博客 介绍如果您从大数据开始,通常会被众多工具,框架和选项所困扰。 在本文中,我将尝试总结其成分和基本配方,以帮助您开始大数据之旅。 我的目标是对不同的工具进行分类,并试图解释每个工具的目的以及它如何适应生态...
- 2017-03-07 10:37回答 1 已采纳 The tutorial you're following is quite old, so if you want follow the tutorial there are two optio
- 2014-07-01 19:14回答 1 已采纳 This is usually implemented by having separate versions of the field in the schema for each langua
- 2020-08-11 11:19回答 1 已采纳 https://blog.csdn.net/dufufd/article/details/52456691
- 2020-11-20 13:35摊牌人生的博客 二是,松散的文本,查询的话基本都是基于like,而join和like是数据库的性能杀手,与最求高效快速的理念相违背。所以我们需要一种和sql完全不同的数据检索方式,由此引出了solr。 1. 安装部署 1.
- 2015-07-13 08:36回答 1 已采纳 http://www.cnblogs.com/likehua/archive/2015/04/29/4465514.html
- 2023-12-10 09:29程序员Forlan的博客 本文详细介绍了Solr搜索引擎的概念、与Lucene的比较区别、安装与配置方法,以及如何使用SolrJ管理索引库。此外,还通过案例实现了创建一...文章还讨论了如何添加、更新、删除和查询文档,以及如何使用SolrJ进行这些操作
- 2018-02-28 22:27公众号【禅与大数据】,欢迎订阅的博客 接下来是根据索引查询hbase中数据. 实测,查询索引数据,确实相当快,main方法测试,7200条数据,只需要1秒.查询hbase数据,同样数量数据,25个列,用了5秒,之前我们在3台集群上测试hbase查询,1万条,用了3秒,这里应该还有...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作