关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
XW-YYDS
2017-06-20 05:07
采纳率: 100%
浏览 2786
首页
已采纳
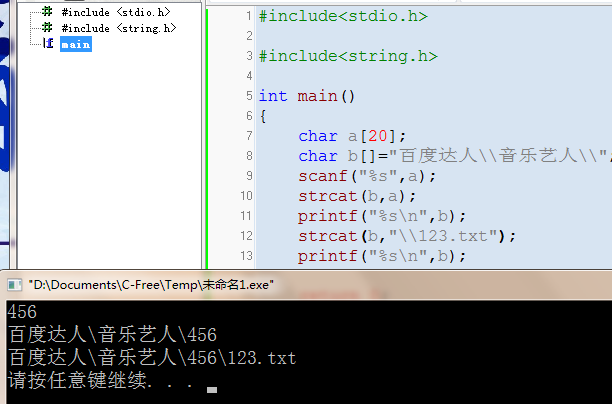
C语言读取文件时候的路径问题
读取的文件路径类似这样:
键盘输入:鹿晗
路径: D:\鹿晗.dat
实现的过程如下图,但是路径会出现问题,求大佬解释,在线等..
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
结题
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
XW-YYDS
2017-06-20 05:35
关注
找到解决方案啦 \ 用 \\表示就可以啦
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
1
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
C语言
批量
读取文件
路径
到txt
2021-08-21 10:23
在
C语言
中,批量
读取文件
路径
到TXT文件是一项常见的任务,特别是在系统编程或文件管理应用中。要实现这个功能,我们需要理解
C语言
中的文件I/O操作、字符串处理以及目录遍历。以下将详细介绍如何使用
C语言
来实现这一...
C语言
中获取文件完整
路径
的实用指南
2024-10-08 13:12
1. **文件操作**:读写文件时,必须提供文件的完整
路径
,以免发生
路径
错误,导致找不到文件的情况。 2. **日志记录**:记录日志时,记录文件的完整
路径
有助于后续追踪文件的来源,增加日志的可用性。 3. **用户界面*...
C语言
实现按行读写文件
2020-08-25 09:41
C语言
实现按行读写文件
C语言
实现按行读写文件是编程语言中的一项基本操作,掌握这种方法对 programmer 的编程能力和编程思维具有重要影响。在本文中,我们将详细介绍 C 语言实现按行读写文件的方法,并提供了详细...
C语言
读写txt文件数据
2023-10-12 15:39
本篇将详细讲解如何使用
C语言
读取和写入TXT文件数据。 首先,读取TXT文件的关键在于使用`fopen`函数打开文件,然后使用`fgets`或`fscanf`来读取数据。在提供的示例中,`fopen`函数被用来打开名为"input.txt"的文件...
C语言
读取目录和文件信息.zip
2022-10-01 11:53
2、递归读取目录,获取目录中所有的子目录和文件
路径
。 3、获取文件信息,包括文件类型(目录、普通文件等)、文件大小、文件的时间属性(创建时间、修改时间、访问时间)等。 4、将 time_t 类型的时间...
C语言
文件操作(文件读写)
2022-02-04 01:23
木唐枝的博客
本文主要介绍
C语言
中文件操作的相关内容(例:文件读、写等相关函数)。 一、文件 在对计算机的使用中我们几乎离不开文件。例如常见的有word 文档,txt文本文件,图片文件、音频文件等。 1.什么是文件? 文件是以...
c语言
文件读写操作代码
2024-09-05 19:43
文件
路径
指明了文件的位置,而打开模式则决定了文件的读写方式,例如“r”表示读取模式、“w”表示写入模式、“a”表示追加模式、“r+”则为读写模式。在打开文件后,程序应检查`fopen`函数的返回值是否为`NULL`,以...
c语言
文件读写操作代码.txt
2024-12-11 13:50
此外,在实际开发过程中还需要注意文件
路径
的正确性、错误处理机制的完备性以及内存管理等方面的
问题
。例如,在读取或写入大量数据时,需要考虑文件指针的定位、缓冲区大小和数据处理效率等因素。而在多线程或并发...
c语言
文件读写操作代码 包含注释和说明
2024-10-07 09:20
C语言
中文件读写的基本步骤包括:打开文件、读写文件、关闭文件。使用标准库函数fopen()可以打开文件,返回一个文件指针,该指针用于后续的读写操作;使用fclose()函数可以关闭文件,确保所有缓冲区内的数据被写入...
c语言
-文件的读写操作(上)
2024-01-24 23:48
PYSpring的博客
本篇文章介绍
c语言
的文件读写操作。
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告

 分享
分享


