
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
import re
import sys
def main():
haltsParse()
def haltsParse():
answer = []
url = "https://www.nasdaqtrader.com/trader.aspx?id=TradeHalts"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
bs = BeautifulSoup(html, "html.parser")
list = bs.find_all("div",{"id":"divTradeHaltResults"})
element = list
print(html)
if __name__=="__main__":
main()
以上是我的python代码。我想要爬取的网页链接为https://www.nasdaqtrader.com/Trader.aspx?id=TradeHalts
在这个网页里面,我想要爬一个表格里面的数据,表格为

我按F12得到的网页html代码中,表格的数据是存在的,下图里面的tbody里面就是表格数据
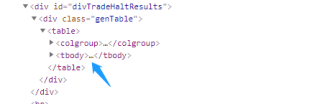
但是当我运行我的python代码,python给我的反馈为这个div里面是空的






