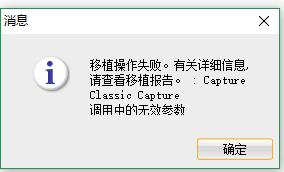
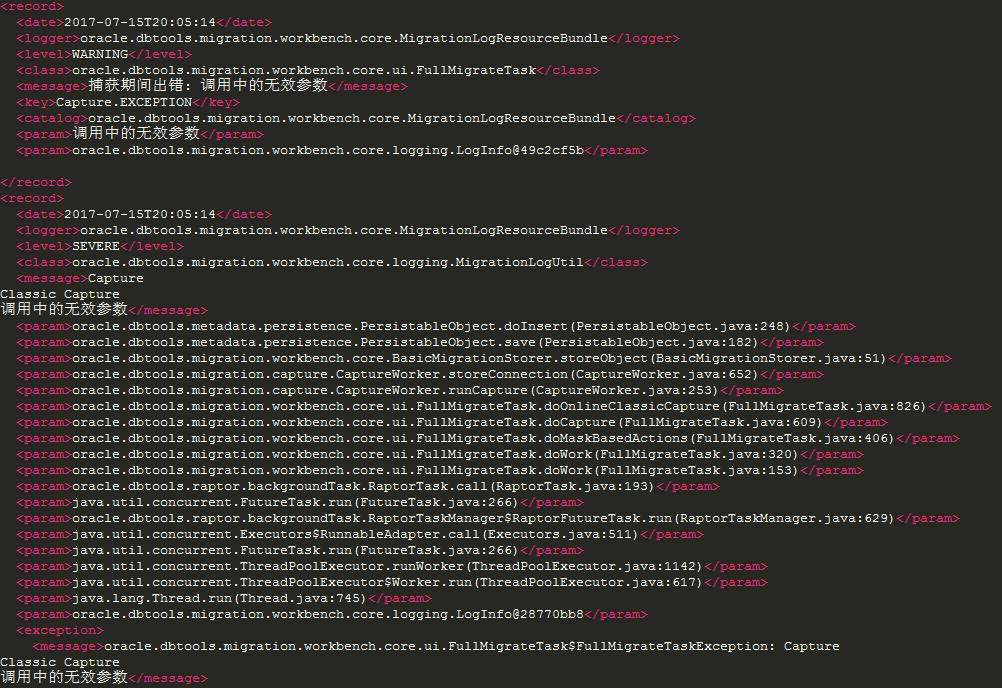
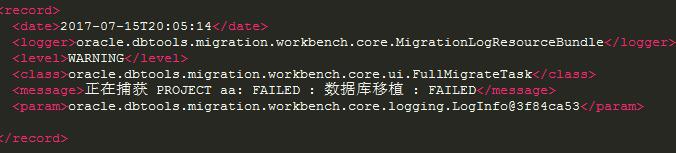
在移植到Oracle操作的最后一步,点击完成后报错,请问大佬们有什么看法,请指点
收起
http://blog.csdn.net/u012814041/article/details/17530141
报告相同问题?

 分享
分享



