我使用的是Scrapy爬虫,目前需要爬取的网页格式内容如下: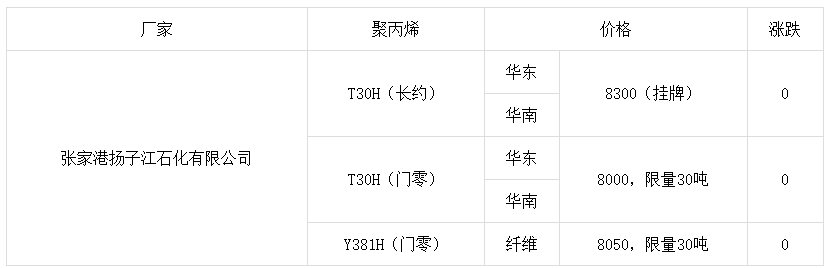
HTML代码如下:
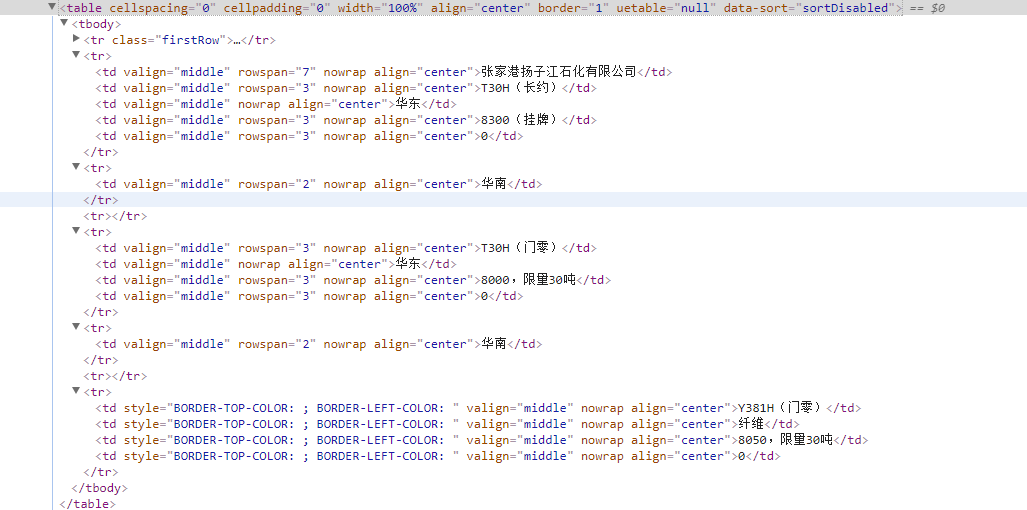
除去标题外,一共是7行,即7个
标签,但实际上显示的表格只有5行数据,因为有2个tr数据是一样的,如第二个“华南”中用到了"rowspan=2",那么第三个就没写了。现在我需要的形式是,我的item[ ]每一次循环tr的时候,都能获取到五个数据(也就是第一个tr中的五个td内容),我的Item如下:

那么请问在已知外循环tr数量的情况下,我该如何遍历获取?

我使用的是Scrapy爬虫,目前需要爬取的网页格式内容如下:
HTML代码如下:
除去标题外,一共是7行,即7个
标签,但实际上显示的表格只有5行数据,因为有2个tr数据是一样的,如第二个“华南”中用到了"rowspan=2",那么第三个就没写了。现在我需要的形式是,我的item[ ]每一次循环tr的时候,都能获取到五个数据(也就是第一个tr中的五个td内容),我的Item如下:
那么请问在已知外循环tr数量的情况下,我该如何遍历获取?
 分享
分享


