url='https://www.zhihu.com/people/yang-ze-yong-3/following'
page=urllib.request.urlopen(url).read()
soup=BeautifulSoup(page)
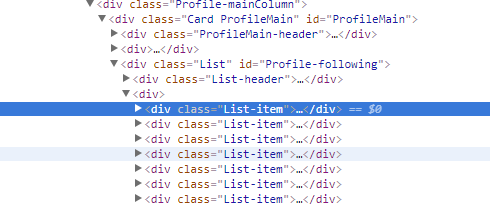
items=soup.find_all('div',{'class':'List-item'})
结果只返回前3条List-item...新手求助

url='https://www.zhihu.com/people/yang-ze-yong-3/following'
page=urllib.request.urlopen(url).read()
soup=BeautifulSoup(page)
items=soup.find_all('div',{'class':'List-item'})
结果只返回前3条List-item...新手求助
 分享
分享
因为zhihu网页不是静态html页面,截图中的html代码是浏览器渲染后最终的代码,不是URL对应的原始html代码。
1.Chrome按F12,点击network。F5刷新页面,第1个URL对应的Response是原始html代码。分析它,重新修改python脚本。
2.使用phantomjs渲染后再获取html代码
分享




