



详细图片
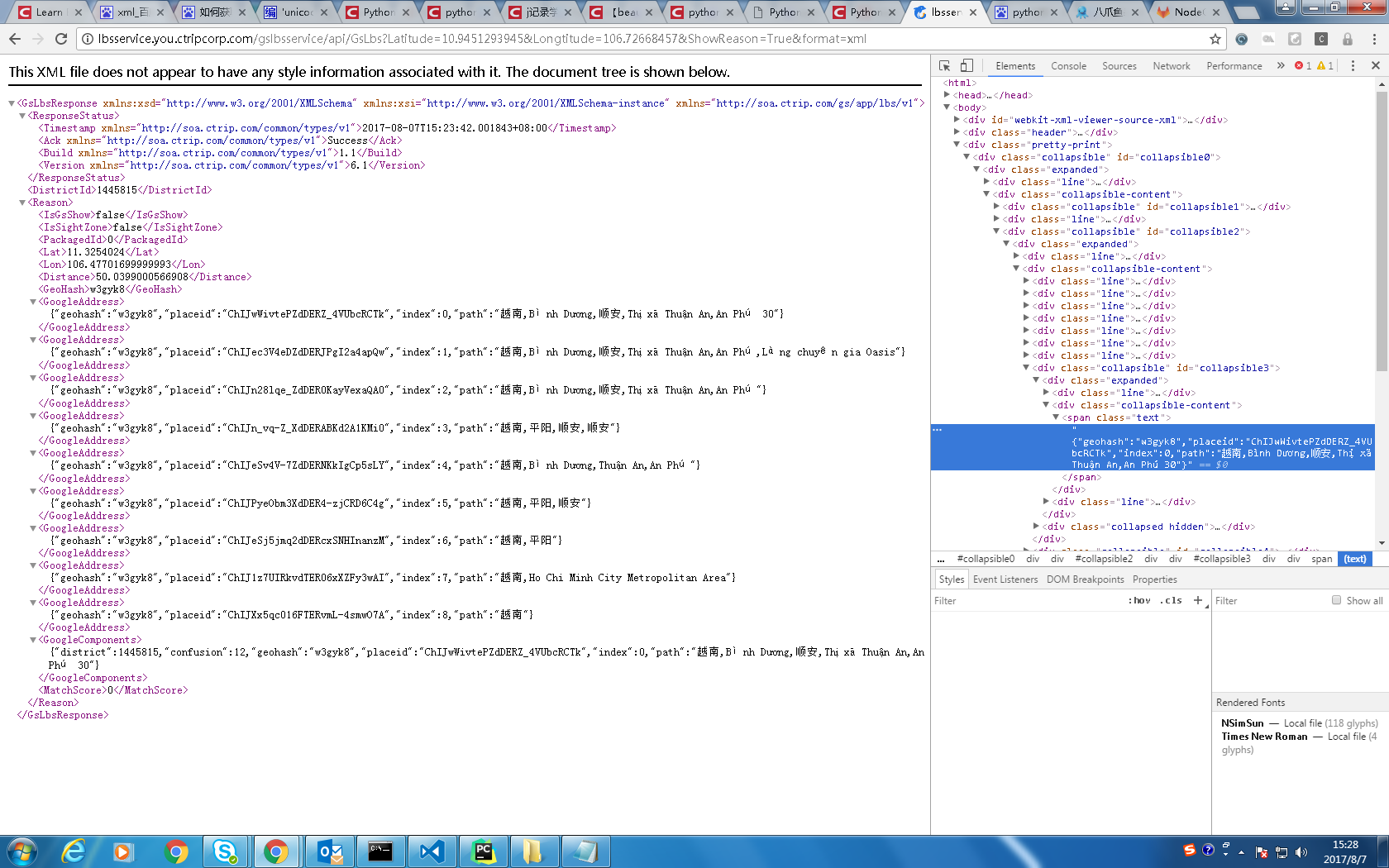
小弟刚学习爬虫,公司有个相关的记录需要我爬取一下,请问各位大神我怎么样能够定位到图中蓝色的部分
页面已经爬取放在了soup中,我自己的方法是
res_node=soup.find('span',class_='text')
但是死活不出数据,请问问题是出在哪里?先谢谢各位了

详细图片
小弟刚学习爬虫,公司有个相关的记录需要我爬取一下,请问各位大神我怎么样能够定位到图中蓝色的部分
页面已经爬取放在了soup中,我自己的方法是
res_node=soup.find('span',class_='text')
但是死活不出数据,请问问题是出在哪里?先谢谢各位了
 分享
分享
























