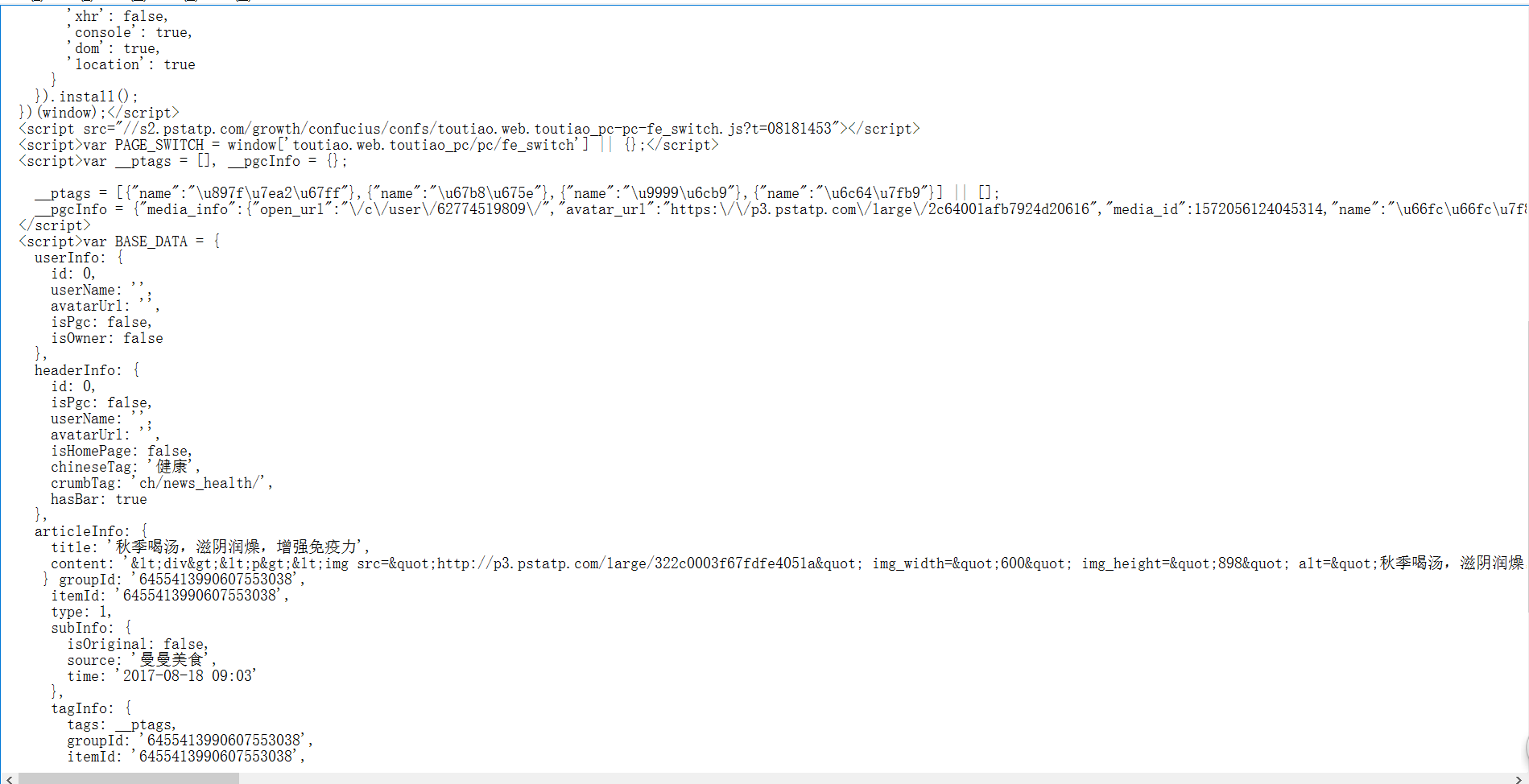
有个功能需要在网上抓取一些数据,本身数据格式是纯html格式的,但是后来别人网站的数据而是改变了,如下.我应该如何获取其中的某个节点的数据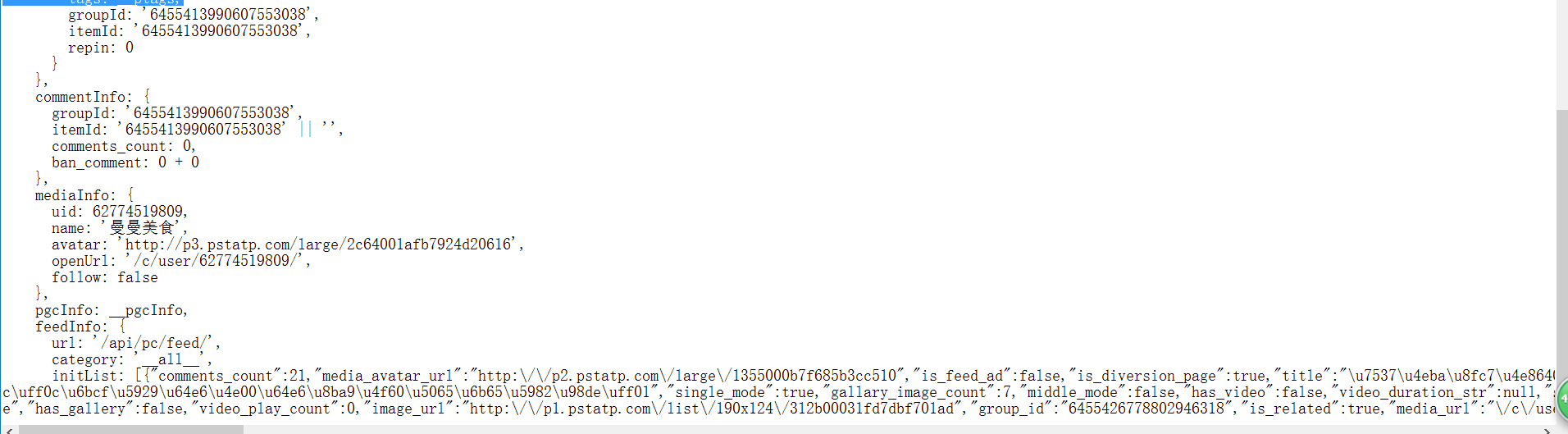图片说明](https://img-ask.csdn.net/upload/201708/18/1503043666_578750.png)图片说明](https://img-ask.csdn.net/upload/201708/18/1503043657_25325.png)

JAVA如何对抓取到的html文本进行解析和数据处理

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

8条回答 默认 最新
- 2024-10-01 09:27JavaScript则用于处理前端逻辑,实现用户交互界面和动态数据显示,使得用户能够在页面上直观地查看和管理小说数据。 整个系统由41个文件组成,其中包括21个Java源文件,它们是系统的核心,涵盖了从网络请求的发送与...
- 2023-07-15 11:45**HTML解析器jsoup简介** ...总结来说,jsoup是Java开发中处理HTML的强大工具,它的易用性和灵活性使其在网页抓取、内容解析、数据提取等场景中广泛应用。通过学习和掌握jsoup,开发者可以更高效地与HTML文档进行交互。
- 2024-10-05 03:35该项目不仅仅是一个简单的展示源码,它涉及到的内容非常广泛,从后端的数据抓取,到前端的数据展示,再到软件的整体构建和配置,都有详细的文件说明和结构规划。它不仅能够作为一个学习Jsoup和HTML解析的示例,还...
- 2025-10-16 16:26而所有的这些数据处理流程,都是基于Java语言的高效性能和良好的跨平台特性来实现的,这使得该搜索引擎不仅功能强大,而且运行稳定,易于维护和升级。 在提供给用户的实际使用体验上,该校园搜索引擎具备了快速响应...
- 2021-10-05 11:32【标题】:使用Java的HTML解析器实现...通过Jsoup,开发者可以轻松实现自动化网页抓取和数据处理任务,同时保证代码的可读性和维护性。结合JavaScript,可以构建出动态更新的Web应用程序,实时获取和展示抓取的内容。
- 2021-11-14 21:28【Java HTML解析器实现网页抓取与...它的强大功能包括解析HTML、选择器查询、安全处理和输出清理,使得在Java环境中进行Web数据处理变得更加便捷。结合前端的JavaScript定时调用,可以构建出自动抓取并更新内容的系统。
- 2018-03-16 10:45口口口口口口口的博客 在后台处理文章摘要的时候,涉及到怎么处理带HTML标签数据本人一共找到了两种解决方法:1、调用插件HtmlParser 简介htmlparser是一个纯的java写的html解析的库,主要用于改造或提取html。用来分析抓取到的网页信息是...
- 2022-06-02 16:21HTML解析器jsoup是Java库,专为处理真实世界的HTML而设计。它提供了一种方便、安全的方式来抓取和操作Web页面数据。...通过学习和使用这个库,你可以提升你的Web数据处理能力,更好地服务于前后端开发。
- 2024-12-03 21:54dsndnwfk的博客 Beautiful Soup为Python开发者提供了一种强大且简单的方法进行网页数据抓取。Beautiful Soup官方文档网络爬虫与数据解析教程。
- 2024-07-15 03:45考呀数学的博客 提取HTML中的文本并换行是一种常见的需求,特别是在从网页上抓取数据并进行处理时。在Java中,我们可以利用Jsoup来实现这一功能。Jsoup是一个用于解析、处理HTML文档的开源Java库,它提供了方便的API来处理HTML结构...
- 没有解决我的问题, 去提问

