一个mysql表有40W条数据。
表结构如下!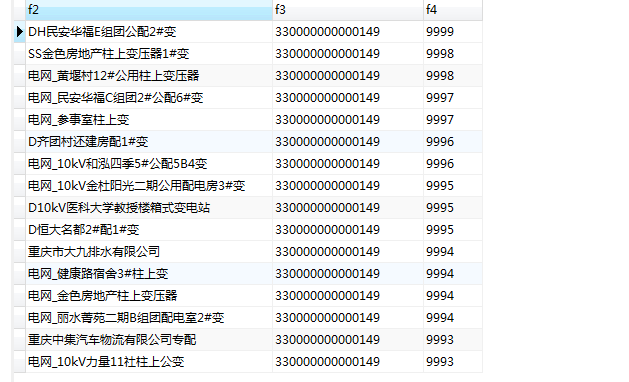
问题是:获取f3重复字段的前十条数据。
考虑性能!!!

mysql语句与性能优化问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

10条回答 默认 最新
 一盏魂灯渡佳人 2017-08-25 04:44关注
一盏魂灯渡佳人 2017-08-25 04:44关注你这个问题就有不合理的地方,f3重复字段可能有很多种 比如 f3字段有10条a重复 10w条b重复 那么你究竟要取出哪一个重复字段的前10条呢?如果是所有f3有重复字段的所有重复项的前10条,那么查出来就不只10条啊。
解决 无用评论 打赏举报 分享
- 2021-03-23 09:49本资料"海量数据性能优化.rar"主要聚焦于如何在大数据环境下提升MySQL的运行效率和响应速度,确保系统的稳定性和可扩展性。下面将详细探讨相关知识点。 1. **索引优化**:索引是提高查询速度的关键。正确使用主键、...
- 2020-12-15 15:49在处理大数据时,优化导入策略至关重要,这不仅可以提高效率,还可以避免因长时间无响应导致的用户体验问题。如果你具备编程能力,编写自定义的导入脚本或工具可以提供更高的灵活性和性能。同时,理解如何有效地利用...
- 2020-12-16 08:44MySQL大数据查询优化是数据库性能提升的关键,特别是在处理海量数据时,高效的查询能够显著减少等待时间,提高用户体验。本文将分享一些实用的SQL优化技巧,主要关注索引优化和WHERE条件优化。 首先,对于大数据量...
- 2022-08-03 16:39MySQL性能优化是一个涵盖多方面的主题,涉及到数据库设计、SQL语句、索引策略、服务器配置、存储引擎以及硬件层面的优化。以下是对标题和描述中所提及的各个优化方案的详细说明: 1. **SQL 和索引优化** - **SQL ...
- 2025-10-26 17:57为了适应大数据的处理需求,MySQL数据库需要进行性能优化,例如通过调整查询算法、增加缓存机制、优化存储引擎等方式,来提高其处理大数据集时的效率和速度。此外,MySQL数据库还需要与其他大数据处理工具,比如...
- 2024-08-17 21:51J老熊的博客 通过优化DISTINCT查询、使用ID轮询方式处理大分页,以及通过合并SQL和分批次更新减少IO操作,可以显著提升...本文将详细探讨如何优化MySQL中的DISTINCT查询、大数据分页操作,以及如何通过批量更新的优化减少IO压力。
- 2025-06-11 17:41意疏的博客 文章目录 深入解析MySQL Join算法原理与性能优化实战指南 一、Join操作的核心原理 二、MySQL中Join算法详解 1. 基础型:嵌套循环连接(Nested-Loop Join) 1.1 概述 1.2 性能复杂度 1.3 利用索引优化(Index Nested-...
- 2020-09-09 10:55MySQL在处理大数据量时,查询优化至关重要,尤其是对于拥有千万级数据的表。...通过合理规划索引、优化查询语句、控制索引数量以及理解查询优化器的工作原理,可以大大提高大数据环境下的SQL查询效率。
- 2024-11-28 16:48戈壁老孙的博客 在 MySQL 中,索引是一种数据结构,它能让数据库引擎在查询时不必扫描整个表,从而提高查询效率。对于一些大的表(比如用户信息、日志等),没有索引的查询可能会非常慢,甚至在数据量巨大的情况下,导致数据库性能...
- 2025-12-03 14:07作为最为流行的开源关系型数据库之一,MySQL的查询性能优化成为了开发人员和数据库管理员必须掌握的关键技术。为了构建高效且稳定的数据库系统,本文将详细探讨一系列实用的MySQL查询性能优化技巧。 首先,索引是...
- 没有解决我的问题, 去提问

