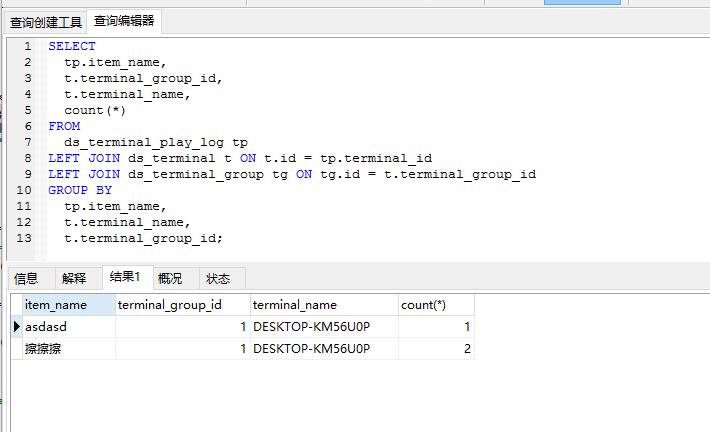
这是执行的sql,在mysql中执行能拿到我想要的结果.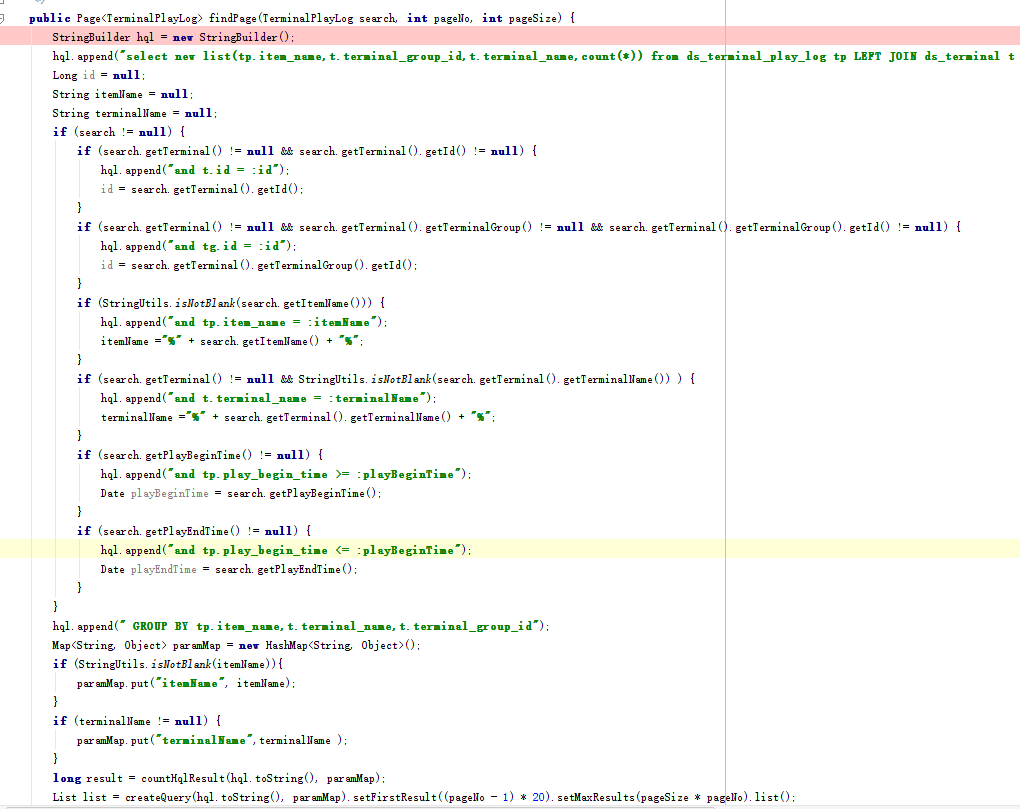
这是我在mysql中拼接的hql, 拼接出来和上面sql一样,能在mysql中直接执行.
但是在hibernate中会给我报错
java.lang.RuntimeException: hql cant auto count .
我推断是因为我实体类没有这个count(*)属性导致的bug
我在网上查说是可以用 new list(需要查询的数据) createQuery(hql).list; 结果还是出现这个异常. hibernate 用的比较少 不知道怎么解决. 求助.

关于Hibernate 查询字段和count(*)的问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 Tsui丶 2017-08-25 06:59关注
Tsui丶 2017-08-25 06:59关注hql中查询的属性需要用实体类中定义的属性, 也不能要用表名,而是实体类名
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2020-09-03 00:50在Java的Hibernate框架中,对数据库数据进行查询是开发Web应用程序时的重要操作。Hibernate作为SSH(Struts、Spring、Hibernate)三大框架之一,提供了一种高效、便捷的方式来处理数据库交互。其中,Hibernate查询...
- 2015-04-02 15:29tracyjuan1719的博客 1.因为count(*)是BigDecimal的值,所以可以用?BigDecimal接收,然后再转换成int类型的,就可以取得count(*)的值 String testSql="select count(*) from test_table where testId=? "; Session session=...
- 2025-06-04 01:27AI应用架构探索者的博客 本文旨在为 Java 开发者提供全面的 Hibernate 统计查询技术指南,涵盖从基础聚合函数到复杂分析查询的实现方法。我们将重点讨论在实际项目中最常用且高效的统计查询模式,避免常见的性能陷阱。文章首先介绍 ...
- 2020-08-31 18:05总的来说,实现Spring MVC 4与Hibernate 4的分页查询功能,需要从分页工具类的设计、DAO层的分页查询方法、Controller层的请求处理以及视图层的展示等多个层面进行考虑和实现。通过这种方式,我们可以为用户提供高效...
- 2023-09-12 09:12狗头版猫头鹰的博客 如果是用Mybatis可能直接一个的动态标签就能解决了,但这家公司用的hibernate,上网一直搜动态之类也给了不少方案。占位符的公用占位顺序,并以count(所有的数字积)进行新的搜索语句就能完成的动态添加距离的方法了...
- 2025-07-08 13:58AI开发架构师的博客 然而,不恰当的Hibernate查询可能导致严重的性能问题。本文旨在为Java开发者提供一套完整的Hibernate查询优化方法论,涵盖从基础配置到高级调优的各个方面。文章首先介绍Hibernate查询的基本原理,然后深入各种优化...
- 2017-08-15 09:17流离岁月的博客 COUNT 返回Long对象 MAX MIN 返回类型是跟所使用的字段类型有关 ...由于接触Hibernate较晚, 一直坚定不移的相信select count() 的返回值的类型的是Long. 一次很偶然的机会发现在一段分页函数里发现在使用select cou
- 2025-06-13 22:02AI应用架构探索者的博客 本文针对Java开发者在使用Hibernate时遇到的“批量数据操作慢”问题,系统讲解Hibernate批量操作的实现方法。批量插入10万条日志数据批量更新用户表的状态字段批量删除过期的订单记录目标是让读者理解Hibernate批量...
- 2021-03-15 16:06weixin_39791386的博客 1. hibernate validator注解在web项目中常常用到,是一个很好用的字段校验器,能够对前端传入的参数进行判断,如是否为空,是否知足正则规定的格式等等。前端2. 假设有一个业务场景,须要判断前端传入的用户是否存在...
- 2025-04-15 21:01AI应用架构探索者的博客 Hibernate 作为 Java 生态中最成熟的 ORM 框架,其版本迭代(如从 5.x 到 6.x)引入新特性的同时也带来兼容性变化。本文聚焦Hibernate 主版本升级(跨大版本,如 5.x → 6.x)的核心注意事项,覆盖依赖管理、配置...
- 没有解决我的问题, 去提问

