在网站上找一个免费的ip代理,在窗口上打印出来自己的代理ip,但是显示结果并没有看到IP的有关记录,全是网易上的网页内容好像,哪位大神可以帮我解惑!!!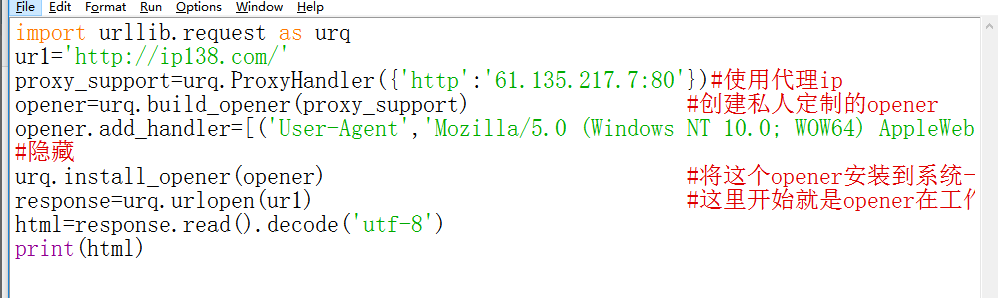


关于python爬虫代理ip的问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新

- 2021-09-06 17:15回答 4 已采纳 那你至少需要研究一下多线程的技术,否则你主线程已经阻塞住了,写什么代码也不执行啊
- 2021-03-28 15:50回答 2 已采纳 把https://去掉试一下看: PROXY = "111...:4221" chrome_opt = WebDriver.ChromeOptions() chrome_opt.add_argume
- 2021-09-09 14:53回答 4 已采纳 使用try catch维护,发现疑似失效ip就给个对应标记,标记达到一定数量就删除对应ip
- 2020-01-10 12:02Python爬虫代理IP池,根据自己需求数量搭建代理IP池保存到本地,调用方法返回池中随机一条可用IP信息,随用随取,十分方便
- 2022-05-07 09:18回答 2 已采纳 request中的参数proxies
- 2023-03-07 10:15回答 1 已采纳 在Python爬虫中使用代理服务器可以通过设置urllib或requests的proxies参数来实现。 下面是一个使用代理服务器的示例代码: import requests proxy = {
- 2021-03-25 14:18回答 4 已采纳 换代理,或在requests.get时加长超时设置,timeout=20。
- 2020-01-06 11:25这里面有无数个ip地址,用于爬虫方面 ip.pkl文件可以由python的pickle库中的load函数导入成链表
- 2023-02-08 13:16回答 3 已采纳 十分感谢,我已经解决问题了,原因是部分ip代理无效导致下载的文件损坏
- 2023-04-06 07:18回答 4 已采纳 引用新必应根据您提供的代码,可能是代理IP出现了问题导致获取到的内容不是百度的。可能的原因有以下几个: 代理IP失效或过期。如果您使用的代理IP已经失效或过期,可能会导致请求被重定向到其他网站,从而得
- 2022-08-23 15:02回答 4 已采纳 重定向了,可考虑解析响应再请求,或上selenium
- 2020-09-16 12:12主要介绍了Python爬虫设置ip代理过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
- 2021-09-04 09:43回答 1 已采纳 这个是代理连接不上的问题,IP质量有问题
- 2020-09-18 13:03主要介绍了Python爬虫使用代理IP的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
- 2020-12-25 00:56在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来。不过呢,闲暇...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 微信公众号自制会员卡没有收款渠道啊
- ¥15 stable diffusion
- ¥100 Jenkins自动化部署—悬赏100元
- ¥15 关于#python#的问题:求帮写python代码
- ¥20 MATLAB画图图形出现上下震荡的线条
- ¥15 关于#windows#的问题:怎么用WIN 11系统的电脑 克隆WIN NT3.51-4.0系统的硬盘
- ¥15 perl MISA分析p3_in脚本出错
- ¥15 k8s部署jupyterlab,jupyterlab保存不了文件
- ¥15 ubuntu虚拟机打包apk错误
- ¥199 rust编程架构设计的方案 有偿