

这段代码,当我点Execute Selection in Console时候,可以正常运行,并且结果和教材一致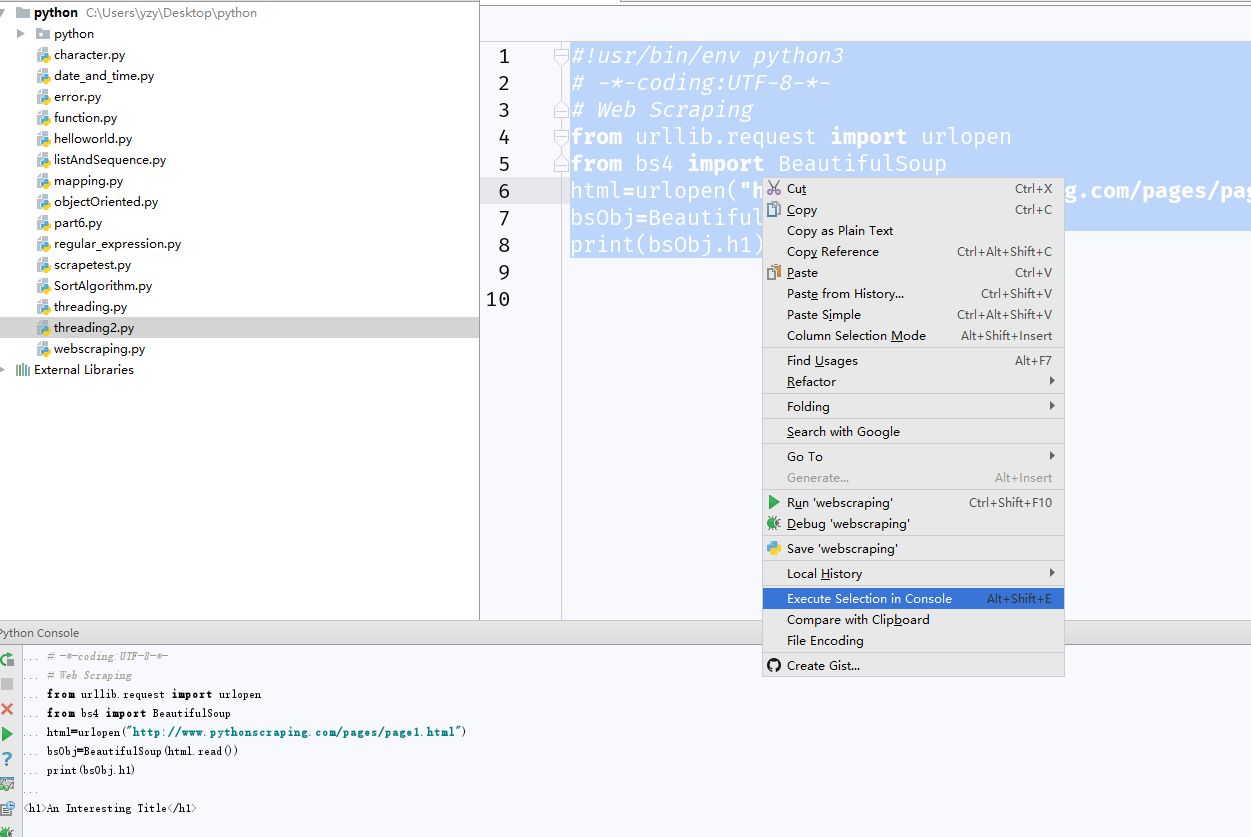
但是我直接运行这个文件时,就开始报错了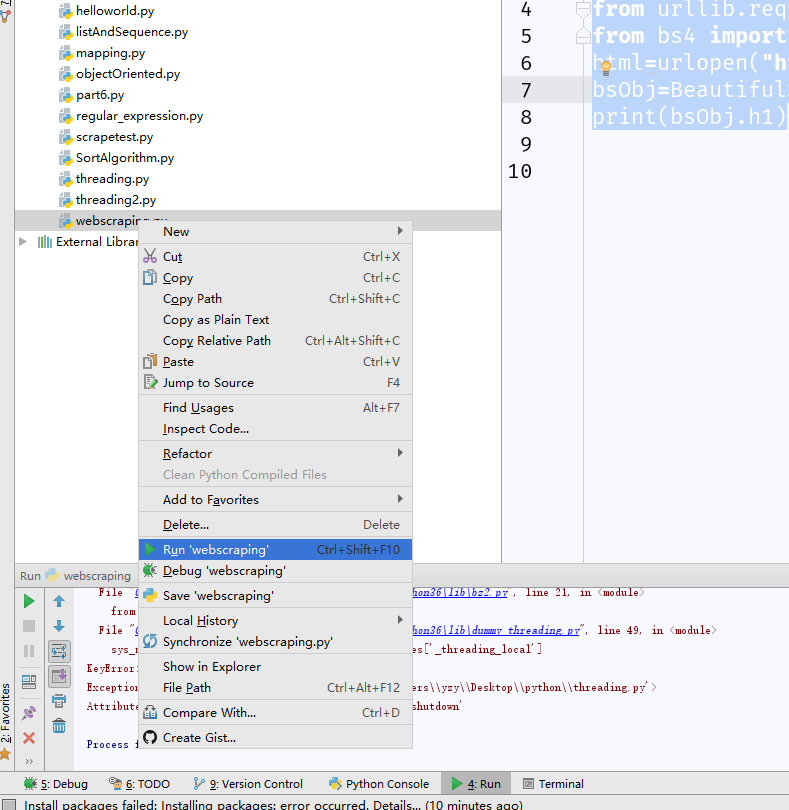
这是怎么回事呢??
错误信息如下:
C:\Users\yzy\AppData\Local\Programs\Python\Python36\python.exe C:/Users/yzy/Desktop/python/webscraping.py
Traceback (most recent call last):
File "C:\Users\yzy\AppData\Local\Programs\Python\Python36\lib\bz2.py", line 19, in
from threading import RLock
ImportError: cannot import name 'RLock'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/yzy/Desktop/python/webscraping.py", line 4, in
from urllib.request import urlopen
File "C:\Users\yzy\AppData\Local\Programs\Python\Python36\lib\urllib\request.py", line 98, in
import tempfile
File "C:\Users\yzy\AppData\Local\Programs\Python\Python36\lib\tempfile.py", line 43, in
import shutil as shutil
File "C:\Users\yzy\AppData\Local\Programs\Python\Python36\lib\shutil.py", line 22, in
import bz2
File "C:\Users\yzy\AppData\Local\Programs\Python\Python36\lib\bz2.py", line 21, in
from dummy_threading import RLock
File "C:\Users\yzy\AppData\Local\Programs\Python\Python36\lib\dummy_threading.py", line 49, in
sys_modules['_dummy_threading_local'] = sys_modules['_threading_local']
KeyError: '_threading_local'
Exception ignored in:
AttributeError: module 'threading' has no attribute '_shutdown'
Process finished with exit code 1





