为什么我新建scala那一步,在new project里面左侧选择scala,右侧就是没有scala的选项呢,只有SBT\Activator\IDEA这三个选项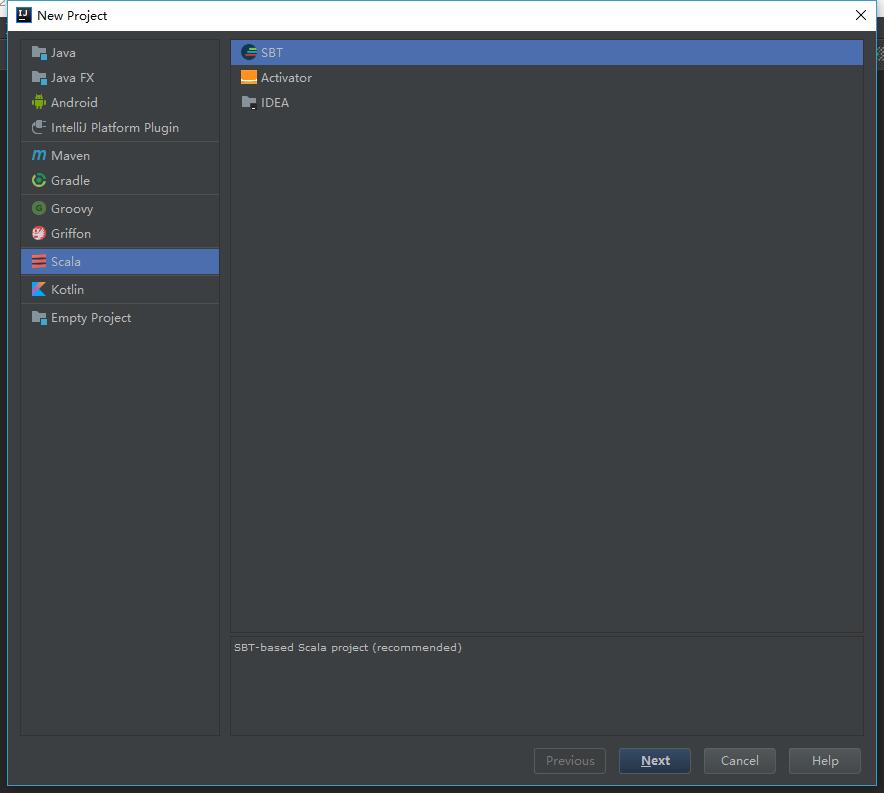

intellij创建scala项目没有scala选项

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

8条回答 默认 最新

- 2022-03-09 21:06zhangz1z的博客 一、下载Intellij IDEA插件Scala 二、安装Scala SDK https://www.scala-lang.org/download/ 建议下载*.zip文件,免安装,然后把scala目录下的bin目录添加到系统路径,这样cmd输入scala就可以启动 scala -version --...
- 2020-08-25 22:16IntelliJ IDEA 下 Maven 创建 Scala 项目的方法步骤 IntelliJ IDEA 是一个功能强大的集成开发环境(IDE),它提供了多种项目模板和插件来帮助开发者快速创建和开发项目。Scala 是一种基于 Java 的编程语言,它提供...
- 2021-02-05 16:03设置项目先决条件为了参与Scala插件开发,您需要: IntelliJ IDEA 2020.1或更高版本以及兼容版本的Scala插件JDK 8 (可选,但建议)在IDEA中启用“ ”建立将此存储库克隆到您的计算机$ git clone ht
- 2020-08-18 22:34因为是第一次创建,没有scala SDK,如果默认点击Finish按钮,scala项目建立后将找不到scala class,也就是不能编写scala程序。因此,需要点击scala SDK右边的create,在弹框中显示了scala SDK版本,可以使用download...
- 2020-04-18 16:53sixgold的博客 Intelli JDEA 创建Scala项目的三种不同方式 ...
- 2023-01-01 20:42qq_45691577的博客 1.新建project2.最好把它重命名成scala然后发现依然无法new一个Scala文件如果你没有安装scala环境,先安装scala 的 sdk,或者在ide里下载scal插件。弄好之后,将scala添加到你的module里添加之后就可以了。
- 2020-09-07 17:31在使用IntelliJ IDEA(简称Idea)这款强大的Java开发工具时,有时会遇到无法创建Scala类的问题。本文将深入探讨这个问题的根源,并提供一系列解决方案,帮助开发者顺利地在Idea中创建Scala类。 首先,当Idea中没有...
- 2022-12-09 17:22大数据张老师的博客 IntelliJ IDEA(简称IDEA)是一款支持Java、Scala和Groovy等语言的开发工具,主要用于企业应用、移动应用和Web应用的开发。IDEA在业界被公认为是很好的Java开发工具,尤其是智能代码助手、代码自动提示、重构、J2EE...
- 2024-10-09 15:06帅气而伟大的博客 2.此时新建Scala会出现红色,需要在模式里导入Scala配置。选择project structure,点击module,查看dependencies发现只有Java jdk...1.在IDEA里new project——>java里选择Scala——>next后给项目输入名称——>finish。
- 2021-02-05 20:46示例Scala项目。 以上所有内容的IntelliJ IDEA设置。 捆绑包是: 一键式。 它不需要安装,更不用说管理权限了。 您可以简单地提取存档并运行该应用程序。 预先配置。 它不需要初始配置。 默认设置已经包括所有捆绑...
- 没有解决我的问题, 去提问

