
我要分析tomcat日志,需要过滤掉不需要的东西
192.168.9.230 - - [24/Apr/2017:19:38:18 +0800] "POST /dvr-gateway/api/genl/paging/device HTTP/1.1" 200 214
比如这一句,我就只想要文件路径和IP地址,该怎么写?用filter可以过滤掉除时间以外的任何数据,但是时间在变,该怎么去过滤?
换句话说我就是在做一个单词统计,统计出每个IP出现的次数和访问文件路径的次数,我能过滤成这样,唯独时间不知道该怎么办了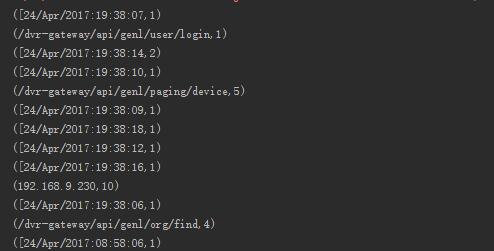
这是我的代码





