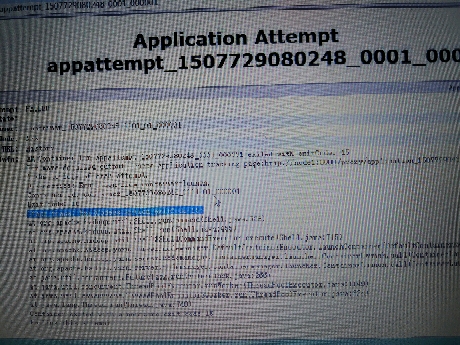
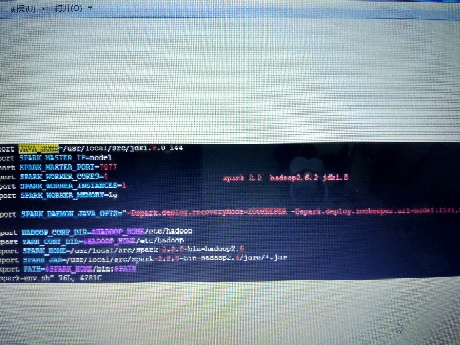
这是一个仿照网上例子,自己学习测试的。用scala编写写了一个wordCount的例子,在myEclipse上是可以运行的,并可以得出结果。现在将例子导出jar包,然后放到hadoop集群上运行,出现如下错误:Stack trace: ExitCodeException exitCode=15跪求各路大神帮忙, 这个问题已经困扰我一个星期了,网上也找了很久,没找到解决办法。没有多少分了 。。。非常感谢!!!环境: hadoop2.6.2 spark2.2 jdk1.8 scala2.2hadoop集群应该是没有问题的,浏览器可以打开50070的页面下面是spark on yarn的环境:export JAVA_HOME=/usr/local/src/jdk1.8.0_144export SPARK_MASTER_IP=node1export SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=1export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=1gexport SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181"export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopexport SPARK_HOME=/usr/local/src/spark-2.2.0-bin-hadoop2.6export SPARK_JAR=/usr/local/src/spark-2.2.0-bin-hadoop2.6/jars/*.jarexport PATH=$SPARK_HOME/bin:$PATHWordCount例子:object wc { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("wc") val sc = new SparkContext(conf) val text = sc.textFile("test.txt") val words = text.flatMap(line => line.split(" ")) val pairs = words.map(word => (word, 1)) val results = pairs.reduceByKey(_+_).map(tuple => (tuple._2 , tuple._1 )) val sorted = results.sortByKey(false).map(tuple => (tuple._2 , tuple._1 )) sorted.foreach(x => println(x)) sc.stop() }}错误信息:Application Attempt State: FAILEDAM Container: container_1507729080248_0001_01_000001Node: N/ATracking URL: HistoryDiagnostics Info: AM Container for appattempt_1507729080248_0001_000001 exited with exitCode: 15For more detailed output, check application tracking page:http://node1:8088/proxy/application_1507729080248_0001/Then, click on links to logs of each attempt.Diagnostics: Exception from container-launch.Container id: container_1507729080248_0001_01_000001Exit code: 15Stack trace: ExitCodeException exitCode=15:at org.apache.hadoop.util.Shell.runCommand(Shell.java:538)at org.apache.hadoop.util.Shell.run(Shell.java:455)at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211)at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)Container exited with a non-zero exit code 15Failing this attempt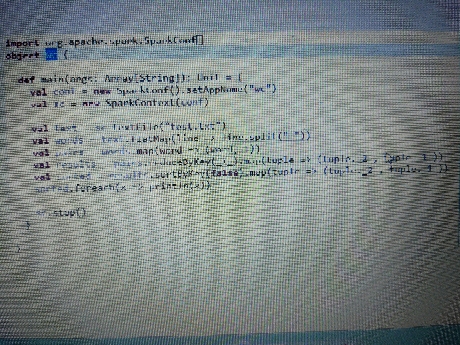

spark集群运行错误:15

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

- 2023-01-17 22:05回答 2 已采纳 这是一个连接Doris服务器失败的错误,具体原因可能是Doris服务器无法连接或网络故障导致的。
- 2022-11-29 13:16回答 1 已采纳 1、目前pyspark.sql.types支持的数据类型:NullType、StringType、BinaryType、BooleanType、DateType、TimestampType、Decim
- 2022-06-23 13:55回答 1 已采纳 Hadoop和Spark都是处理大数据的框架。就象你说关系型数据库,这只是一个概念,但是代表了一系列的含意,比如数据是结构化的,基于关系模型存储的。而MySQL、Oracle、SqlServer这些就
- 2022-07-01 23:31博_采_众_长的博客 当实际运行Spark应用程序时,我们会从集群管理器那里请求资源来运行它。根据应用程序的配置,我们可能获得一个运行Spark驱动器的机器资源,或者可能获得的是我们Spark执行器的计算资源。在Spark应用程序执行过程中,...
- 2023-04-21 16:19回答 2 已采纳 这篇博客: spark安装踩坑中的 2.JNI error 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读: 报错:A JNI error has occurred, pleas
- 2022-10-31 14:14回答 4 已采纳 集群规模是怎么样的?(10核,128g内存 几台机器?)代码逻辑是怎么样的,单纯的读库的操作吗?还是有大量的shuffle操作EXECUTOR_num EXECUTOR_core 参数分别设置的多少
- 2022-12-07 13:39回答 1 已采纳 缺少jar包:org/slf4j/impl/StaticLoggerBinder,添加一下slf4j-nop-xxx.jar
- 2022-05-17 22:53浊酒南街的博客 目录1、Spark 发展史2、 Spark 为什么会流行 1、Spark 发展史 2009 年诞生于美国加州大学伯克利分校 AMP 实验室; 2014 年 2 月,Spark 成为 Apache 的顶级项目; Spark 成功构建起了一体化、多元化的大数据处理体系...
- 2022-12-15 15:54
 Spark 读取 Hive 数据报错 NoSuchMethodError : org.apache.spark.sql.catalyst.catalog.SessionCatalog
hive
spark
大数据
回答 1 已采纳 22/12/15 15:32:44 INFO SparkContext: Invoking stop() from shutdown hook集群资源不足,且动态资源分配申请的executors、内存
Spark 读取 Hive 数据报错 NoSuchMethodError : org.apache.spark.sql.catalyst.catalog.SessionCatalog
hive
spark
大数据
回答 1 已采纳 22/12/15 15:32:44 INFO SparkContext: Invoking stop() from shutdown hook集群资源不足,且动态资源分配申请的executors、内存 - 2022-08-27 16:48回答 1 已采纳 webui上能看到各个stage运行的阶段,在哪个节点上执行的以及执行信息,希望能帮到你
- 2021-10-25 15:00回答 2 已采纳 你好,我是有问必答小助手,非常抱歉,本次您提出的有问必答问题,技术专家团超时未为您做出解答本次提问扣除的有问必答次数,将会以问答VIP体验卡(1次有问必答机会、商城购买实体图书享受95折优惠)的形式为
- 2019-04-02 18:51萧邦主的博客 实战概览一、实战内容二、大数据实时流处理分析系统简介1.需求2.背景及架构三、实战所用到的架构和涉及的知识1.后端架构2.前端框架四、项目实战1.后端开发实战1.构建项目2.引入依赖3.创建工程包结构4.编写代码5.编写...
- 2022-05-19 19:51回答 3 已采纳 你用的beeline方式连接的吧 beeline连接是有限的当连接超出的时候就会出问题 你尝试一下 直接连接hivecli 应该会好一点
- 2022-07-13 14:07数据带你飞的博客 目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkCore、SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 ...
- 2021-05-04 16:51赵广陆的博客 目录1 Spark 是什么2 Spark 四大特点2.1 速度快2.2 易于使用2.3 通用性强2.4 运行方式3 Spark 框架模块3.1 Spark Core3.2 Spark SQL3.3 Spark ...Spark MLlib3.5 Spark GraphX3.6 Structured Streaming4 Spark 运行模式...
- 没有解决我的问题, 去提问

悬赏问题
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题
- ¥15 slam rangenet++配置
- ¥15 有没有研究水声通信方面的帮我改俩matlab代码
- ¥15 ubuntu子系统密码忘记
- ¥15 保护模式-系统加载-段寄存器
- ¥15 电脑桌面设定一个区域禁止鼠标操作
- ¥15 求NPF226060磁芯的详细资料