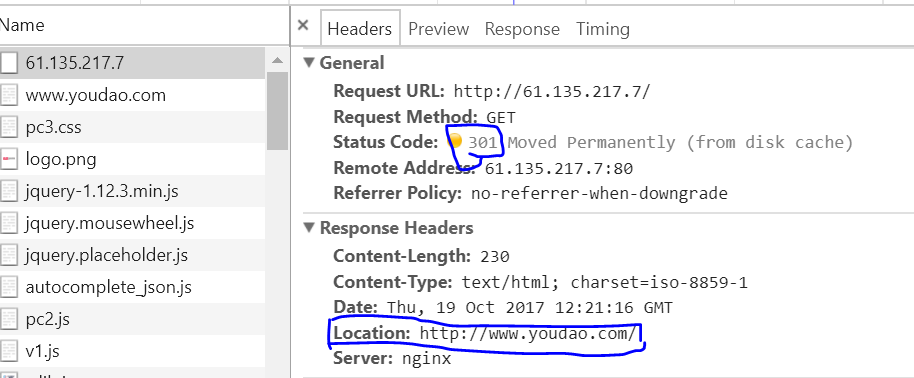
proxies={
"http": "http://61.135.217.7:80", "https":"https://113.108.130.210:808"
}
请求方式: requests.get(url="a 网址",proxies=proxies}
代理ip来源于 http://www.xicidaili.com/nn/
按照这样的格式爬取的数据,结果爬取的到的内容不是a网址的内容,而是代理中 ['http']的代理的网页内容。
如果 requests.get(url="a 网址",proxies=None} 不使用代理,则可以获取到网页的正确的内容?
不知道怎么回事