大概有两种方式吧,1抓请求,2看代码逻辑。我用1抓请求的来说,以Chrome为例:
- 打开开发者工具,输入网址,点击第二页,查看network面板,点击主网址(第一条),在Response里得出那些item是html源码返回的,不是网页再去ajax之类的请求来的
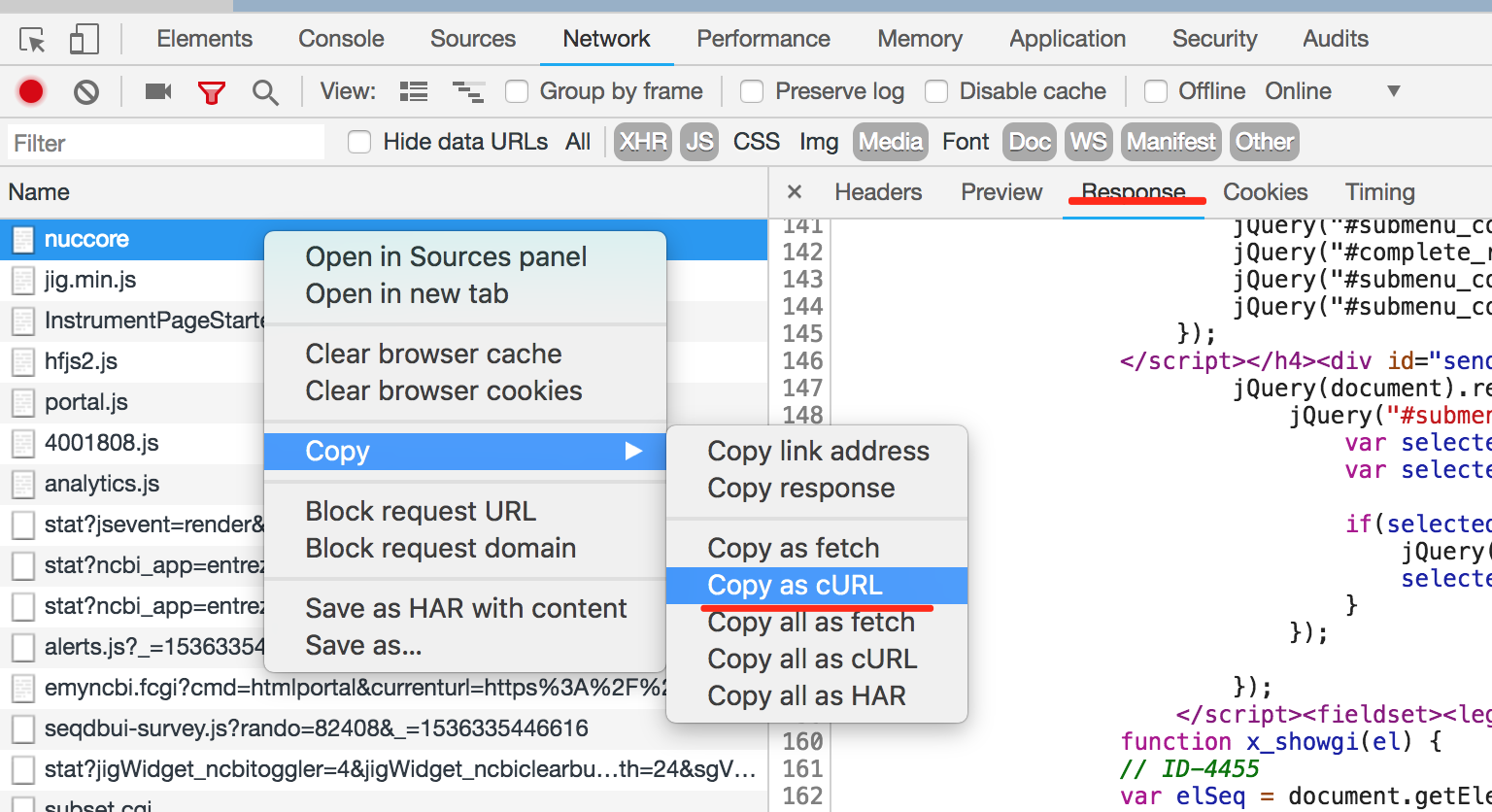
- 右键copy as curl(为例),copy出来便于后续处理:
curl 'https://www.ncbi.nlm.nih.gov/nuccore' -H 'authority: www.ncbi.nlm.nih.gov' -H 'cache-control: max-age=0' -H 'origin: https://www.ncbi.nlm.nih.gov' -H 'upgrade-insecure-requests: 1' -H 'content-type: application/x-www-form-urlencoded' -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8' -H 'referer: https://www.ncbi.nlm.nih.gov/nuccore/?term=trocholejeunea' -H 'accept-encoding: gzip, deflate, br' -H 'accept-language: zh-CN,zh;q=0.9' -H 'cookie: ncbi_sid=39715999B9263251_0079SID; WebEnv=1ZCmaGvRzY3zpI_IAgfXI0JqPi895YkU0mGNTLkrEK3TGUQc-jpFe6a-PFL72MblpoSCI13v40tnx_Fz87Eb-5BcmOwB4DJf6kGAM%4039715999B9263251_0079SID; _ga=GA1.2.2002142930.1536320297; _gid=GA1.2.770582215.1536320297; _gat=1; starnext=MYGwlsDWB2CmAeAXAXAJgLy2ogTrAXgGQDM60ArsMAPZ6EAs6AJtcAM7kC2hAbM6x24B2dAAtEnEIQAc6VAAZCATmawAZgENyIRIQCM89LlajqIWACtY5OBv170e/aSFL9jNrA05go/Xw0QKT0RTRBPfVkwiIV0YiUhPQBWJVSAISVUHlQAYWkDeUKiovoAMULcgDpOAH1UVEJUByxcAgBSYgBBCipaWA7OlnYuAYA5AHlRgFFGjAB3BcroYAAjMCWQTiWwUUqAc2oAN0bGFrx8AZ6aOizMbHPLymv+rqHBRpEz9q6rvoG3kZdCbTRqyL4XIQ5X54NqQgGcWE5YEzVAqPT0eiKYiGJSFEgOdGYkgYaTEegkUjRWAkRi4cjU4hJRwYrF8DGoJIkESocnEWQ8XG8lRJPR6BqY9DSaS4hgOVEy+gYaAaRBgQ7UjHoUAQGAIXT0JnivhUhgiXHSBiyDkW+gqDTAVXqtq5AAOGj2sBq4GgkGdUL1hCShnEiBdbAGztKkYWcyWq3W0E2212B0Okeh/VQUeIpUQsBwCOIABFjL4zJZrLZncRAw4pvcCABlACebDznFQlQACvXWvhKqMnn1Ko3YABHenLT0AJVgHB0bC7GjgIEqvfONSXHpw3fd1KSGFGeud8g6MySpEJiiSjAN5O9kBqys4sHQ66brfbnZ7Df7g96eAjuOk7ADOc7aIgi7LrAq7vvgm57juW7UsuoFtrQACSTDoJwGhgMs1DYC0AA0cGlLQ3CoXOiC0DkIAaGwbCjBoL7oG6ez4SqYCEcRqqIOYNTLkwNTsfmxE0ER2DiWYxGeOq0A1DQIAANw2CA1AaEwcBIGgdx9iQZBDnQjDwrw/DDMIYgSFIVqKCoTDqFoOj6IYpamOYVg2F49iOPoGBqRpTDOOgrjuOgnjeL4/joIEwShIEER6FECXUrE8SJCk6SZNkeQFMUxRlBUOTVHUDRNHpDw/EZLyDAIgKdMiszoDGcZrBsWzQDs+xHCcFXfN01WNHw4KPABNWmagny/qNzz/HVhYNZMKJgtNkIZoi8KIo1qLMkS2LoLiWIEiyxKSmSFLoCaZJGDg9IkEyV4kGyiqcsQ3K8vySh6DwJDCmKnIStK8g1vQcqpIoipkFx6oMIwAWadp+pMuSF67dejBNA0STI4qgZ8CKP1JCI15Wik14qIoPCGJTBIckIQA' --data 'term=trocholejeunea+&EntrezSystem2.PEntrez.Nuccore.Sequence_PageController.PreviousPageName=results&EntrezSystem2.PEntrez.Nuccore.Sequence_Facets.FacetsUrlFrag=filters%3D&EntrezSystem2.PEntrez.Nuccore.Sequence_Facets.FacetSubmitted=false&EntrezSystem2.PEntrez.Nuccore.Sequence_Facets.BMFacets=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.sPresentation=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.sPageSize=20&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.sSort=none&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.FFormat=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.FSort=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.CSFormat=fasta_cds_na&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.GFFormat=gene_fasta&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.Db=nuccore&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.QueryKey=1&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.CurrFilter=all&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.ResultCount=79&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.ViewerParams=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.FileFormat=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.LastPresentation=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.Presentation=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.PageSize=20&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.LastPageSize=20&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.Sort=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.LastSort=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.FileSort=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.Format=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.LastFormat=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.PrevPageSize=20&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.PrevPresentation=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.PrevSort=&CollectionStartIndex=1&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_ResultsController.ResultCount=79&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_ResultsController.RunLastQuery=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_ResultsController.AccnsFromResult=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Entrez_Pager.cPage=1&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Entrez_Pager.CurrPage=2&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Entrez_Pager.cPage=1&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.sPresentation2=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.sPageSize2=20&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.sSort2=none&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.TopSendTo=genefeat&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.FFormat2=docsum&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.FSort2=&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.CSFormat2=fasta_cds_na&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_DisplayBar.GFFormat2=gene_fasta&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_MultiItemSupl.Taxport.TxView=list&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_MultiItemSupl.Taxport.TxListSize=5&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_MultiItemSupl.RelatedDataLinks.rdDatabase=rddbto&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Sequence_MultiItemSupl.RelatedDataLinks.DbName=nuccore&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Discovery_SearchDetails.SearchDetailsTerm=%22Trocholejeunea%22%5BOrganism%5D+OR+trocholejeunea%5BAll+Fields%5D&EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.HistoryDisplay.Cmd=PageChanged&EntrezSystem2.PEntrez.DbConnector.Db=nuccore&EntrezSystem2.PEntrez.DbConnector.LastDb=nuccore&EntrezSystem2.PEntrez.DbConnector.Term=trocholejeunea&EntrezSystem2.PEntrez.DbConnector.LastTabCmd=&EntrezSystem2.PEntrez.DbConnector.LastQueryKey=1&EntrezSystem2.PEntrez.DbConnector.IdsFromResult=&EntrezSystem2.PEntrez.DbConnector.LastIdsFromResult=&EntrezSystem2.PEntrez.DbConnector.LinkName=&EntrezSystem2.PEntrez.DbConnector.LinkReadableName=&EntrezSystem2.PEntrez.DbConnector.LinkSrcDb=&EntrezSystem2.PEntrez.DbConnector.Cmd=PageChanged&EntrezSystem2.PEntrez.DbConnector.TabCmd=&EntrezSystem2.PEntrez.DbConnector.QueryKey=&p%24a=EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Entrez_Pager.Page&p%24l=EntrezSystem2&p%24st=nuccore' --compressed
- 可以看到有很多请求头与参数,然后就是分析与精简,看哪些是必要参数以及猜测参数意思
- 比如先把请求参数弄成个数组,然后一个个减少来请求,如果响应结果不是想要的,就说明当前减少的那个参数是必须的
String[] params = { "term=trocholejeunea",
"EntrezSystem2.PEntrez.DbConnector.Cmd=PageChanged",
"EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Entrez_Pager.CurrPage=2","省略"};
for (int i = 1; i <= params.length; i++) {
Builder bodyBuilder = new FormBody.Builder();
System.out.println(i);
int j = 0;
for (; j < params.length - i; j++) {
String[] split = StringUtils.splitPreserveAllTokens(params[j], '=');
bodyBuilder.addEncoded(split[0], split[1]);
}
Request request = new Request.Builder().url("https://www.ncbi.nlm.nih.gov/nuccore")
.header("cookie",
"省略")
/* 省略其它header */
.post(bodyBuilder.build()).build();
Response response = new OkHttpClient().newCall(request).execute();
if (!StringUtils.contains(response.body().string(), "AY462401")) {
// 第二页有关键字AY462401,如果响应没有,那params[j]就是必填参数
System.out.println(params[j]);
break;
}
}
- 其它请求内容如header,cookie等参照上一条处理
- 再点第三页,比较与第二页请求内容的变化猜测诸如请求参数等内容的含义
| 请求参数 |
含义 |
| term=trocholejeunea |
你的查询内容? |
| EntrezSystem2.PEntrez.DbConnector.Cmd=PageChanged |
必填 |
| EntrezSystem2.PEntrez.Nuccore.Sequence_ResultsPanel.Entrez_Pager.CurrPage=2 |
页面,1=第1页 |
| EntrezSystem2.PEntrez.DbConnector.LastQueryKey=1 |
必填 |
ps: 没研究为什么直接打开 http://www.ncbi.nlm.nih.gov/nuccore/?term=trocholejeunea 不需要DbConnector.Cmd这些参数
- 结果:用get(query string)或者post(form data)都可以拿到结果,用程序获取会提示requires JavaScript但没关系,items是有的
- 都需要加上.header("Cookie", "ncbi_sid=39715999B9263251_0079SID"),不知道这东西是啥,每次还不一样
- HtmlUnit支持js,但你这里没必要
- 最后:你自己玩吧,可以提高问题的C币么?我答的很累!!!
- 坑:你给的地址是http,点第二页跳的是https






