我就直接上图了
我在详细的说一下我想问的问题点:
为什么我下面的代码执行完并没有扩容,但是允许的个数为2,现在我存了3个???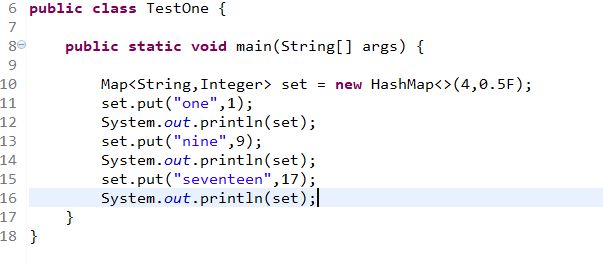

HashMap()中的分组组数与阈值之间的关系是什么?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


7条回答 默认 最新
 lp180361* 2017-11-27 08:17关注
lp180361* 2017-11-27 08:17关注更正一下
null != table[bucketIndex]表示的是数组中hash值取余冲突的情况,也就是说,即使存放的数据数量超过threshold,但是如果存放位置是数组上的闲置位置(为null的位置),那么数组是不会扩容的(充分利用空间)以下是修改后内容
看jdk1.7实现源码
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt>. * (A <tt>null</tt> return can also indicate that the map * previously associated <tt>null</tt> with <tt>key</tt>.) */ public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }indexFor方法是将hash值映射到你数组中的位置中(数组hash值与数组大小的&运算结果),再看addEntry方法
/** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }threshold是容量*加载因子,4*0.5=2,你存第三个确实满足了size >= threshold,但是不满足null != table[bucketIndex],也就是说你有两个key的hash值位运算之后存放在容量为4的数组中空闲位置里(如果下标在同一个位置(hash冲突),则同一个位置上数据以链表的形式纵向存储(假定在数组上的存储为横向存储)),所以没有扩容。至于有的人扩容了有的人没有扩容,那是因为存放的key不一样,所以hash值不一样,hash值不一样位运算结果就不一样,计算结果不一样存储在数组上的位置就不一样,只要存放的位置是闲置的,数组就不会扩容,但是这里有一个上限,当数组存满了,再继续存储便一定会产生冲突,从而扩容(一个优质的hash函数,应当避免散列后冲突的情况,我想当初设计者留下0.75的默认加载因子也应该是出于对hashmap的效率保护,避免过多的链表影响效率,在数组填满75%的空间下,hash冲突的几率应该是不大的)
以下是hash源码,以及获取数组下标源码
final int hash(Object k) { int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } transient int hashSeed = 0; int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }one,two,three没有扩容,但是one,two,three1扩容了,可以从debug看出
下面代码是从源码中提取出来的,用来获取字符串key在数组中的位置
public static void main(String[] args) { System.out.println(indexFor(hash("one"),4)); System.out.println(indexFor(hash("two"),4)); System.out.println(indexFor(hash("three"),4)); System.out.println(indexFor(hash("three1"),4)); } static final int hash(Object k) { int h = 0; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }执行结果
3
1
0
3
three1跟one在数组中的存储位置冲突了,如果不扩容就会在one之后形成并列的链表形式存储,这样会大大影响Hash查询效率
结合之前我的分析,应该不难看出hashmap的扩容机理本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2017-11-21 03:23回答 7 已采纳 更正一下 **null != table[bucketIndex]表示的是数组中hash值取余冲突的情况,也就是说,即使存放的数据数量超过threshold,但是如果存放位置是数组上的闲置位置(为n
- 2022-04-07 21:12回答 2 已采纳 调用 entrySet() 方法 返回 transient Set<Map.Entry<K,V>> entrySet 这个字段属性;transient Set<Map.
- 2022-07-30 22:12回答 1 已采纳 HashMap可以自定义初始化容量,比如传入6,那么hashmap的容量是8,一定是2的n次幂 jdk1.8之后,CHM锁的范围由segement改为node节点 HashMap和CHM转红黑树的条件
- 2020-08-13 11:08小傅哥的博客 存储、删除、获取、遍历,在这些功能中经常会听到链表、红黑树、之间转换等功能。而红黑树是在jdk1.8引入到HashMap中解决链表过长问题的,简单说当链表长度>=8时,将链表转换位红黑树(当然这
- 2022-03-11 16:03回答 4 已采纳 value就是键值对中的“值”,next是当计算出来的index相同,发生碰撞时,把这个节点对象连接到上一个节点对象,形成链表。和你说的并不冲突,next的类型也是Node,存放值的是value。
- 2022-09-09 11:16回答 4 已采纳 Map每个节点是一个NodeNode的键表示key,值表示valueMap部分源码: public interface Map<K,V> { Set<K> keySet
- 2017-05-29 02:44回答 2 已采纳 Entry是一个内部静态类,包含了key,value,next。因为hashmap是数组加链表实现的。在存值时候,通过计算key.hashcode()%Entry[].length,得到要存储的 数
- 2023-10-26 23:56默 语的博客 作为一名Java开发者,熟练掌握集合类是至关...HashMap是Java中的一种数据结构,它提供了一种键值对的映射关系,允许使用键来查找值。在实际开发中,它能够高效地进行数据存储和检索,是Java编程中常用的集合类之一。
- 2022-09-15 14:42回答 1 已采纳 数组扩容之后,需要重新计算索引,原链表的索引也会变化。但是由于hashMap的数组长度是 2的n次方,每次扩容使数组长度 :newlength = 2* oldlength;并且计算索引方法是:has
- 2022-04-24 17:31回答 3 已采纳 Integer a = (Integer) 1; Object b = new Integer(1); 像这个
- 2021-08-16 01:53回答 1 已采纳 public static void main(String[] args) { HashMap<String, String> map = new HashMap<
- 2020-03-04 16:01且听_风吟的博客 什么是HashMap? HashMap底层基于散列(Hash)算法,采用hash表实现键值对集合,继承了AbstractMap,实现了Map接口。最早出现在jdk1.2,允许null键和null值,null键的哈希值为0。需要注意的是HashMap不保证键值对...
- 2022-10-14 17:55回答 1 已采纳 这是java多态的一种思想。使用的时候你不用关心它是hashmap还是linkedHashmap或者别的map,降低了使用者的复杂度。
- 2023-11-15 10:54忆~遂愿的博客 "Java魔法解密:HashMap底层机制大揭秘"一文深入探讨了Java中HashMap的底层机制。通过解密HashMap的工作原理,读者将了解到HashMap是如何通过哈希表实现快速查找的,同时也揭示了在实际应用中如何避免碰撞并确保性能...
- 2021-03-01 22:27hakusai22的博客 JDK1.8_HashMap分析1.HashMap数据结构2. HashMap的基本属性3. 通过hash函数进行计算索引的位置4. HashMap的get()方法5. hashmap的链表getNode()方法获取值6. hashmap的红黑树getTreeNode()获取值7. Hashmap里的find...
- 没有解决我的问题, 去提问


悬赏问题
- ¥20 搭建pt1000三线制高精度测温电路
- ¥15 使用Jdk8自带的算法,和Jdk11自带的加密结果会一样吗,不一样的话有什么解决方案,Jdk不能升级的情况
- ¥15 画两个图 python或R
- ¥15 在线请求openmv与pixhawk 实现实时目标跟踪的具体通讯方法
- ¥15 八路抢答器设计出现故障
- ¥15 opencv 无法读取视频
- ¥15 按键修改电子时钟,C51单片机
- ¥60 Java中实现如何实现张量类,并用于图像处理(不运用其他科学计算库和图像处理库))
- ¥20 5037端口被adb自己占了
- ¥15 python:excel数据写入多个对应word文档