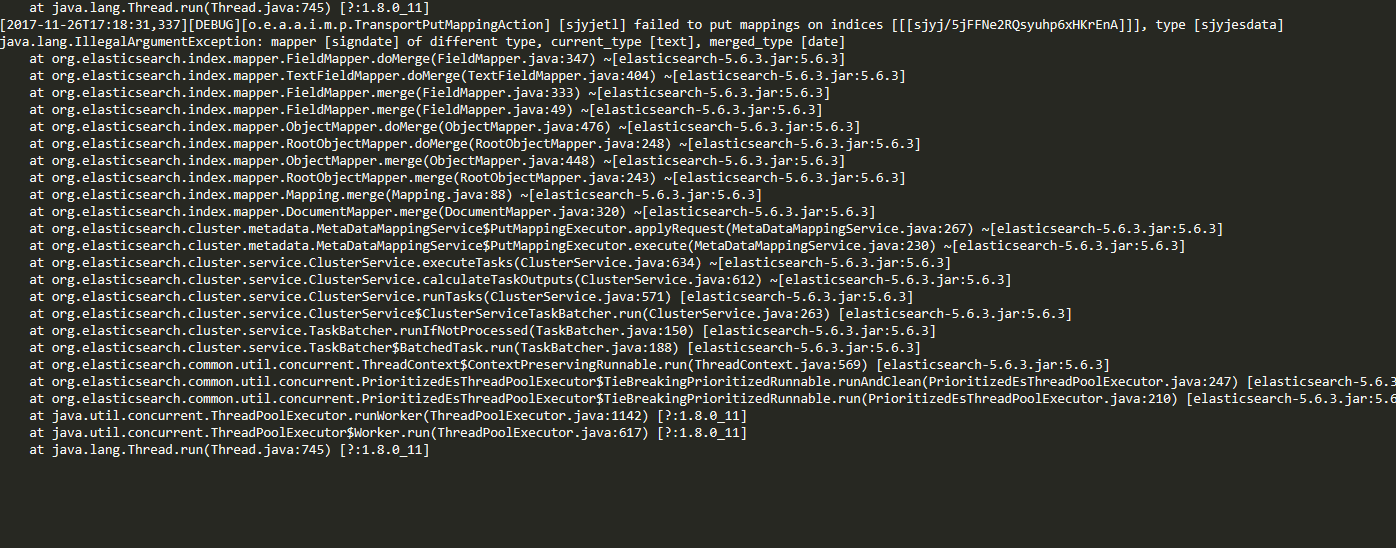
很奇怪的现象,我一共有一千万的数据量,不是一条都不能导入,有时候能导入几千条,有时候 能导入几万条就断了。就是总是报text类型转换为date类型

hive导入es数据date类型转换问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


0条回答 默认 最新
- 2022-02-26 20:05回答 3 已采纳 你好,我是有问必答小助手,非常抱歉,本次您提出的有问必答问题,技术专家团超时未为您做出解答本次提问扣除的有问必答次数,将会以问答VIP体验卡(1次有问必答机会、商城购买实体图书享受95折优惠)的形式为
- 2022-10-18 14:09回答 1 已采纳 SELECT出来的结果是带引号的,说明实际上不是单纯的1,2,3,4,5,而是“x”的字符串,所以无法直接转INT类型
- 2022-06-06 17:18回答 2 已采纳 在window用excel把csv改成\t 分割,建表分割符改成\t
- 2020-08-18 20:29╭⌒若隐_RowYet——大数据的博客 决定采用ElasticSearch(以下简称ES)作为后端搜索引擎服务,然后将符合条件的结果在ES搜索出来反馈给前端展示,但是我的基础数据都是存在数据仓库的Hive表内,这就面临一个问题,如何将Hive表的数据直接导入到ES内...
- 2021-12-19 11:35回答 2 已采纳 查了一些资料,Datax源码的确有点问题,需要修改Datax的源码。参考: datax mysql null不能转为Long 等一些列无法强转问题_大壮的博客-CSDN博
- 2022-10-21 17:22回答 2 已采纳 这是elasticsearch-hadoop RestClient部分的源码,https://github.com/elastic/elasticsearch-hadoop/blob/main/mr
- 2022-07-26 16:15回答 1 已采纳 不能用row format delimited fields terminated by,改用 ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.
- 2020-01-02 17:14xinxindsj的博客 本文将详细介绍利用 ES 与 Hive 直接的数据交互;通过 Hive 外部表的方式,可以快速将 ES 索引数据映射到 Hive 中,使用易于上手的 Hive SQL 实现对数据的进一步加工。 一、开发环境 1、组件版本 CDH 集群版本:...
- 回答 1 已采纳 https://www.cnblogs.com/xuyou551/p/7998846.html
- 2021-11-26 09:06回答 1 已采纳 啊,我知道了,我知道了传入数据的时候,string 不用加引号的
- 2021-10-20 22:56不吃天鹅肉的博客 最近公司需要从es数据库导入到数仓,记录一下遇到的坑。还是蛮多的。首先是用到的库 import csv import threading import time import logging import traceback from datetime import datetime, timedelta import ...
- 2022-05-25 20:11回答 2 已采纳 安装的MySQL上是否创建这个数据库hive的lib目录下是否拷贝了连接MySQL的驱动包hive-site.xml的配置文件中是否配置了MySQL的用户名和密码 这个是我的配置,可以参考一下!
- 2017-10-22 03:19gezooo的博客 项目中遇到ES中的时间格式导入HIVE中,出现异常。 今天晚上有空研究了一下Elasticsearch-hadoop 源码,发现HiveValueReader用的是下面这个方法在解析时间字符串 DatatypeConverter.parseDateTime(value) 没有...
- 2020-06-29 19:55谭正强的博客 有很多种情况下需要将ES的数据同步到hive数仓中进行分析,在此记录下在此过程中遇到的问题。 1、环境说明 ES Version: 7.2.1 Hadoop Version: 3.0.0 elasticsearch-hadoop-7.2.1.jar 2、ES的数据示例 "time" : ...
- 没有解决我的问题, 去提问

