
python 2.7.13, lxml是我命令行安装的应该就是最新了。
我想爬某个论坛里的动画种子,大体思路:
(1)打开 http://bbs.opfans.org/forum.php?mod=forumdisplay&fid=37 会有1个表,读每项的链接。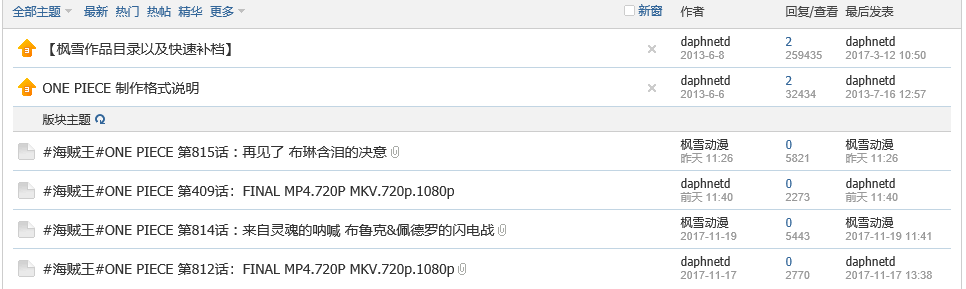
(2)再打开每1项,进入寻找 torrent 的链接。
经观察,需要的链接是在 ignore_js_op 以下的 a 里,但是中间具体夹了几层不一定,外面的层次关系也不一定,所以我就寻找 ignore_js_op 。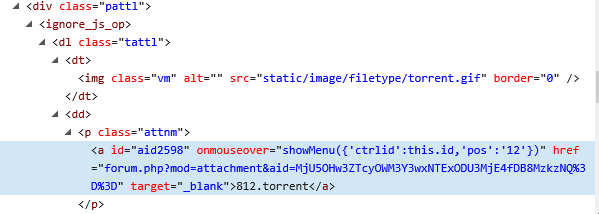
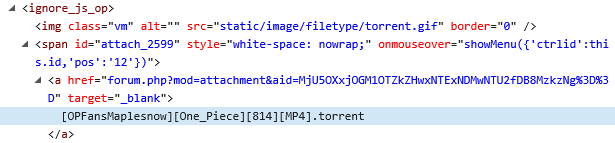
之前匹配不到的原因找到了,经实验发现1个通配符只能配1层。如果是中间层数不定的情况能不能通配?
(对于这个例子我用的是contains()和and,参照http://python.jobbole.com/84689/?utm_source=group.jobbole.com&utm_medium=relatedArticles)
代码:
# -*- coding:utf-8 -*-
import urllib, re, urllib2, lxml
from lxml import etree
'''
Download ONE PIECE torrent.
'''
def getHtml(url):
page = urllib.urlopen(url)
html = page.read().decode('gbk')
#print page.info()
page.close()
return html
HostName = r'http://bbs.opfans.org/'
Html1 = getHtml(HostName + r"forum.php?mod=forumdisplay&fid=37")
Xpath1 = r'//body/div/div/div/div/div/div/form/table/tbody/tr/th/a/@href'
Xpath2 = r'//ignore_js_op/*/a[@href]'
Content1 = etree.HTML(Html1).xpath(Xpath1)
for Line1 in Content1:
if re.match(r'forum\.php.+', Line1):
NewLink = HostName + Line1
print NewLink
Html2 = getHtml(NewLink)
Content2 = etree.HTML(Html2).xpath(Xpath2)
for Line2 in Content2:
print HostName + Line2.xpath(r'./@href')[0]
print Line2.xpath(r'./text()')[0]
结果:
http://bbs.opfans.org/forum.php?mod=viewthread&tid=93&extra=page%3D1
http://bbs.opfans.org/forum.php?mod=viewthread&tid=39&extra=page%3D1
http://bbs.opfans.org/forum.php?mod=viewthread&tid=3939&extra=page%3D1
http://bbs.opfans.org/forum.php?mod=attachment&aid=MjYwMXxlNWUyZjMwZHwxNTExODU1ODA3fDB8MzkzOQ%3D%3D
[OPFansMaplesnow][One_Piece][815][MP4].torrent
http://bbs.opfans.org/forum.php?mod=redirect&tid=3939&goto=lastpost#lastpost
http://bbs.opfans.org/forum.php?mod=viewthread&tid=3938&extra=page%3D1
http://bbs.opfans.org/forum.php?mod=redirect&tid=3938&goto=lastpost#lastpost
http://bbs.opfans.org/forum.php?mod=viewthread&tid=3936&extra=page%3D1
http://bbs.opfans.org/forum.php?mod=attachment&aid=MjU5OXxlYmNlYzc3ZXwxNTExODU1ODA3fDB8MzkzNg%3D%3D
[OPFansMaplesnow][One_Piece][814][MP4].torrent
http://bbs.opfans.org/forum.php?mod=viewthread&tid=3935&extra=page%3D1






