
最近在做一个短文本分类(垃圾和非垃圾两类)的项目,样本数量大概几十万,分词后使用信息增益算法提取出了前3000条分数较高的特征作为分类的字典,但是感觉特征数量还是太多,训练速度太慢,且分类效果也没有很好(比不上简单的朴素贝叶斯)。
于是想到使用RFE算法进行降维。RFE算法的主要思想就是使用一个基模型(这里是S模型VM)来进行多轮训练,每轮训练后,根据每个特征的系数对特征打分,去掉得分最小的特征,然后用剩余的特征构建新的特征集,进行下一轮训练,直到所有的特征都遍历了。
然而,降维后,经交叉验证得到,最优的特征数量仅为27,且经RFE筛选出的前27个特征词也很奇怪,在字典中的排名普遍不是很靠前,在样本中的分布也看不出什么代表性(出现在10万条样本中的次数不多,且分布的倾向性也不高)。
如下图,第一张图是最优的27个特征在样本中的分布,第二张图是信息增益算法得到的字典中排名靠前的特征在样本中的分布。要说明的是,这两张图中的特征几乎不重合。
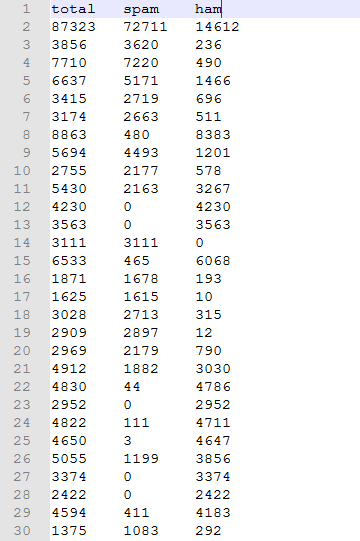
可以看出,许多并不在最优特征中的特征在样本中的分布也非常具有倾向性,可是为什么却在SVM算法中的系数不大以至于被删除呢?
尽管这27个特征看上去特别不靠谱,但令人惊讶的是,仅使用它们训练SVM模型,其分类性能却非常优秀,甚至比3000条特征训练的模型还要好。
这让我非常不解,信息增益算法得到的字典中那么多评分很高的特征,为什么会是这27条评分并不高的特征是最优特征呢?
另外,为什么这27条出现次数如此之少的特征就可以达到比3000条特征还要好的分类性能呢?
若大家对此问题有什么见解,恳请指教!





