已经试过了网上说的删除bd0001.sys文件,重启之后仍然不可以
浏览器是最新版本了

Chrome浏览器黑屏,右下角显示扩展程序崩溃,什么网页都打不开

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


10条回答 默认 最新

- 2020-06-03 22:15回答 1 已采纳 肯定是你的电脑的问题。 我的系统就是windows 7 chrome版本83 没有任何问题。 看看是不是什么加载项有问题。
- 2020-11-19 08:54回答 1 已采纳 <servlet-mapping> <servlet-name>dispatcherServlet</servlet-name> <url-patt
- 2022-08-15 21:15回答 4 已采纳 。。这怎么感觉是chrome崩溃后发送错误报告,导致后续更多问题,得看下chrome目录下,来一个彻底删除,然后再下载
- 2023-10-24 13:37Amo Xiang的博客 本文主要讲解C语言编程环境的搭建,让大家能够编写并运行C语言代码。本文还对一段简单的C语言代码进行了分析,让大家明白了C语言程序的基本结构。
- 2020-11-30 00:28回答 11 已采纳 1、首先把chromedriver.exe放到chrome.exe同级目录下; 2、diriver =webdriver.Chrome(路径) 路径是chromedriver.exe的路径 di
- 2022-11-09 18:59回答 3 已采纳
- 2021-07-20 16:35回答 1 已采纳 声明插件的路径要和本机chrome版本一致 driver_path = r'F:\extends\chrome91\chromedriver.exe' driver_path = r'D:\Tool\
- 2021-12-20 09:56鱼小旭的博客 一般像我这样主攻后端前端要求不高的建议HubilderX,专业前端请选择Hubilder! HBuilder X - Release Notes ====================================== 3.2.16.20211122 修复 代码悬浮提示 某些情况下,HBuilderX出现...
- 2022-03-27 17:57回答 5 已采纳 chromedriver版本要和chome版本相匹配,你可以下载chrome99.0.4844.51稳定版本,然后从这个网址下载对应的驱动http://chromedriver.storage.goo
- 2018-03-18 09:38回答 8 已采纳 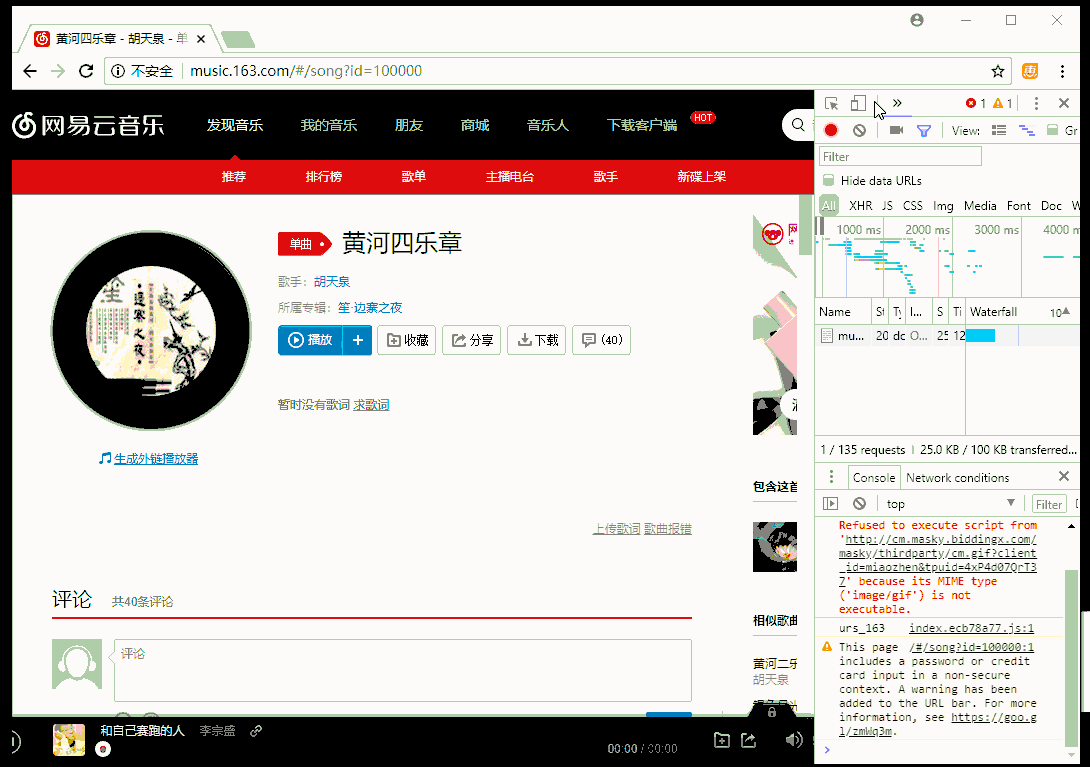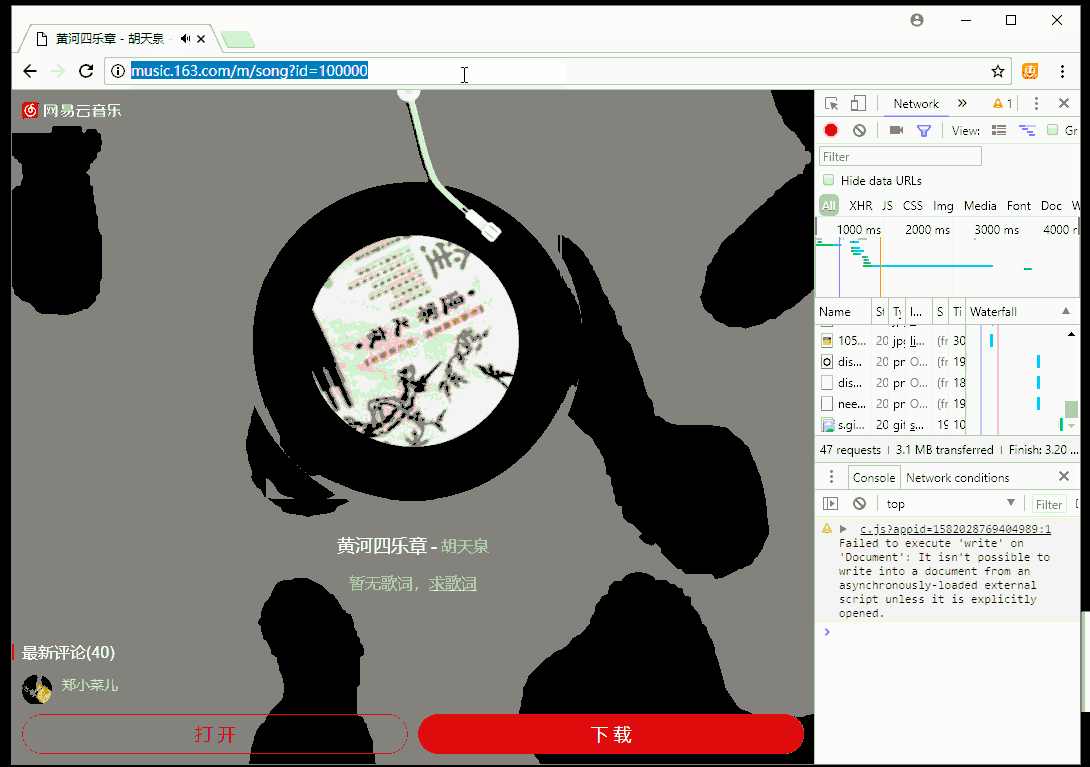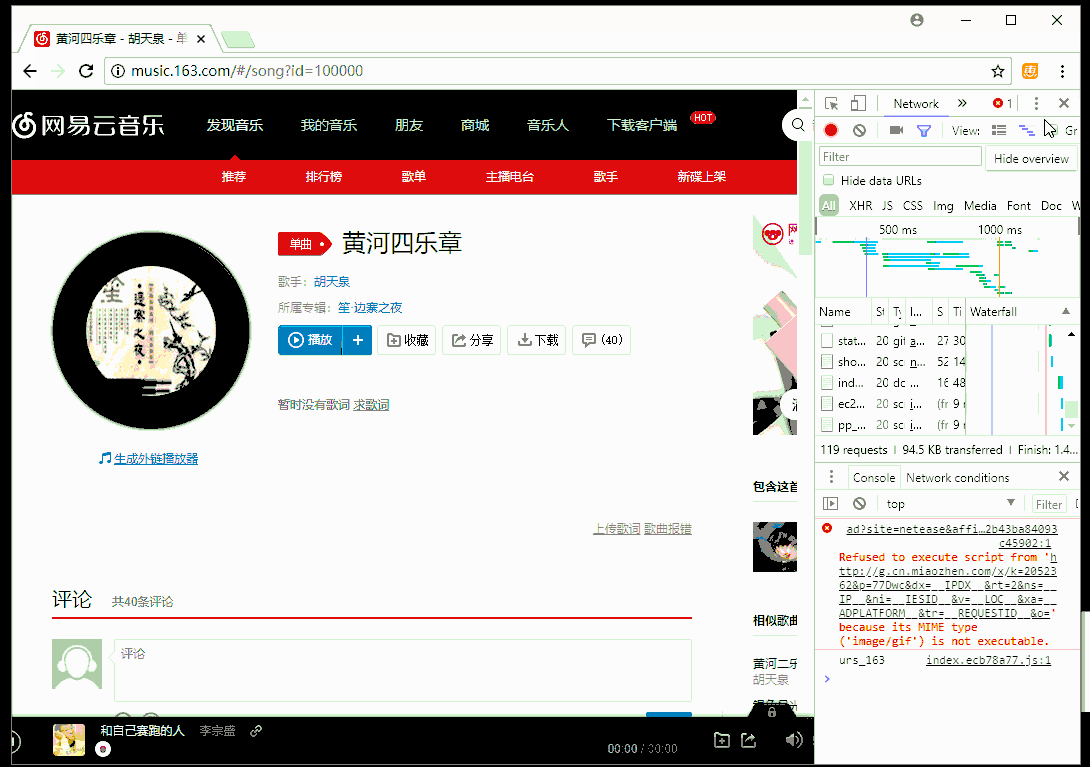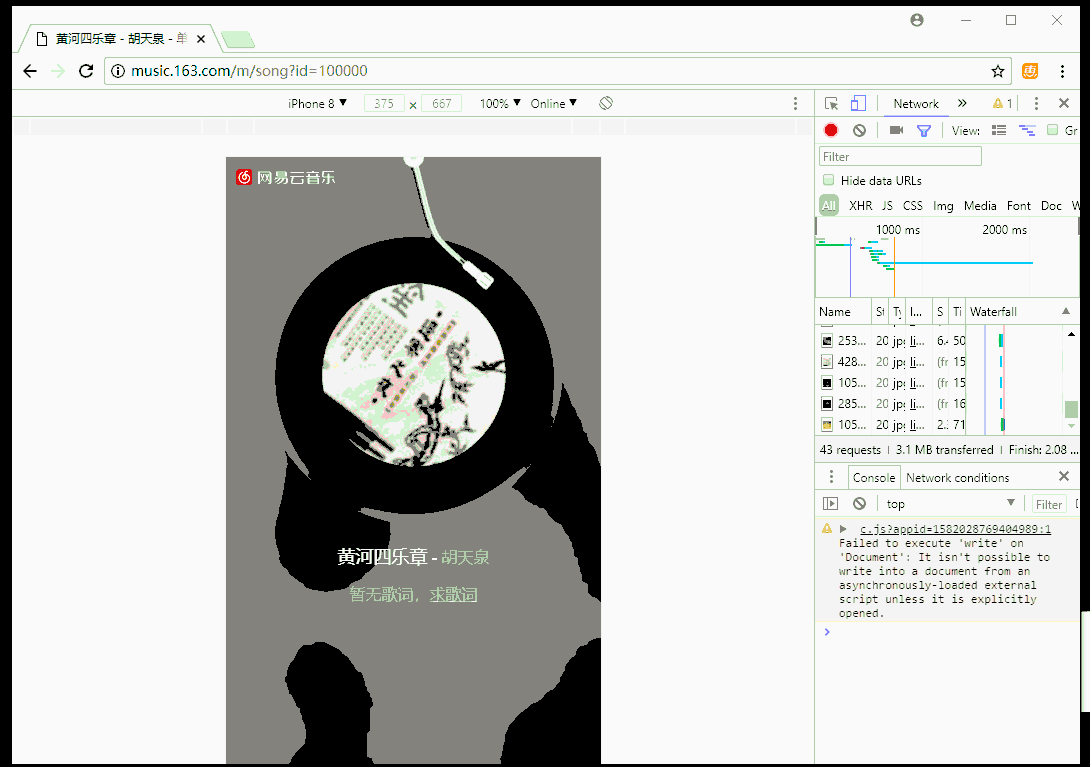 如果已经跳转到m,不会重新跳转,得重新输
- 2021-06-08 08:49回答 3 已采纳 在打印出来的对象上右键. 有个copy object. 会帮你拷贝对象的json字符串. 然后你粘贴到控制台查看即可.
- 2020-07-16 08:51NeXT_Vision的博客 浏览器使用 百度网盘倍速播放 办公工具 笔记本电脑键盘上的fn键 电脑桌面时钟 电脑录屏和手机录屏工具 Adobe PDF阅读器 罗技Logitech无线接收器驱动 设置WIFI热点 设置路由器 文件管理与多终端同步 电脑之间文件同步...
- 2021-10-19 10:10回答 2 已采纳 你这个是系统字体问题,换其他浏览器看看有没有这个问题,如果没有,卸载谷歌再安装试试,最后建议做一下电脑杀毒
- 2020-04-19 00:21wtg4452的博客 题目汇总 共293道题 目录 题目汇总 1 一....二....1.什么是兼容性测试?...4.您所熟悉的测试用例设计方法都有哪些?请分别以具体的例子来说明这些方法在测试用例设计工作中的应用。 10 5.请以您以往的实际工作为例...
- 2020-08-22 14:30自闭火柴的玩具熊的博客 文章目录@[toc]**前言 **关于系统安装...4.修改双系统启动项为win10默认启动二、chrome浏览器与代理配置安装chrome配置代理1.ubuntu系统代理(全局代理)2.chrome中配置代理三、配置开发环境1.Java与MavenJava JDKMave.
- 没有解决我的问题, 去提问


悬赏问题
- ¥50 导入文件到网吧的电脑并且在重启之后不会被恢复
- ¥15 (希望可以解决问题)ma和mb文件无法正常打开,打开后是空白,但是有正常内存占用,但可以在打开Maya应用程序后打开场景ma和mb格式。
- ¥15 绘制多分类任务的roc曲线时只画出了一类的roc,其它的auc显示为nan
- ¥20 ML307A在使用AT命令连接EMQX平台的MQTT时被拒绝
- ¥20 腾讯企业邮箱邮件可以恢复么
- ¥15 有人知道怎么将自己的迁移策略布到edgecloudsim上使用吗?
- ¥15 错误 LNK2001 无法解析的外部符号
- ¥50 安装pyaudiokits失败
- ¥15 计组这些题应该咋做呀
- ¥60 更换迈创SOL6M4AE卡的时候,驱动要重新装才能使用,怎么解决?