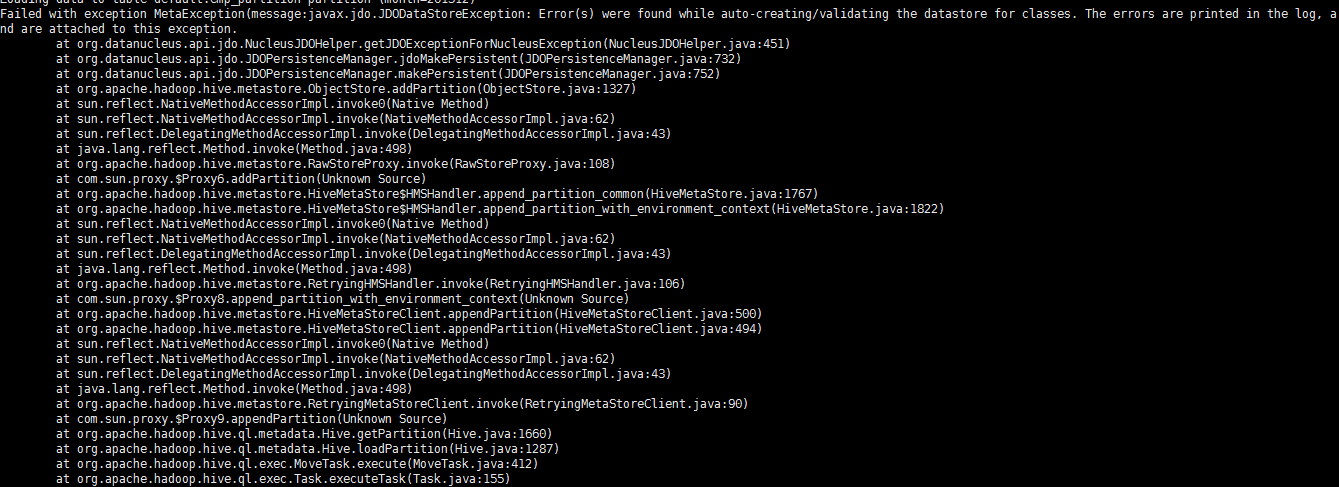
分区表导入数据load data local inpath '/opt/datas/distdata/emp.txt' into table emp_partition partition(month='201512');我修改了mysql的字符集:alter database hive character set latin1;报错如下: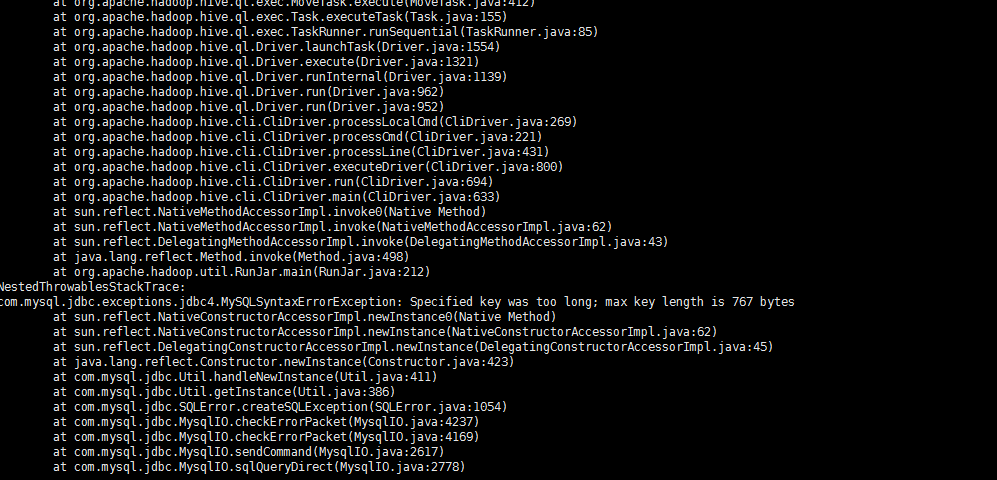
不知道这个问题是怎么回事
文件也上传上去了 select查询就查不出来

大数据hive分区表导入数据的问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

5条回答 默认 最新

- 2025-01-20 20:06此外,文档演示了静态与动态地对分区表导入外部文件夹数据的技术细节;还讲解了内连接、左外连接、右外连接及全外连接等多种表间连接的操作方式,并辅以实例展示每种类型的适用范围及其产生的不同效果。 适用人群:...
- 2020-06-17 21:52我不是忘尘的博客 Hive默认是 静态分区,我们在插入数据的时候要手动设置分区,如果源数据量很大的时候,那么针对一个分区就要写一个insert, 比如说,有很多我们日志数据,我们要按日期作为分区字段,在插入数据的时候手动去添加分区...
- 2022-09-01 14:37树下喝茶聊天的博客 HIVE分区表的全量插入。
- 2023-08-23 23:58大数据与AI实验室的博客 在前面的博客中,我简单介绍了几种向 Hive 表中插入数据的方法。然而更多的时候,我们并不是一条数据一条数据的插入,而是以批量导入的方式。在本文中,我将全面介绍几种向 Hive 中批量导入数据的方法。
- 2021-04-07 10:46小夕Coding的博客 【大数据Hive系列】 Hive分区表和分桶表
- 2024-10-12 23:29Vez'nan的幸福生活的博客 Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。
- 2022-12-07 18:38动态分区、静态分区和混合分区是Hive数据操作语言的高级操作,用于将数据插入到分区表中。动态分区的语法格式如下: INSERT INTO table_name PARTITION (partcol1=val1, partcol2=val2 ...) VALUES (value1, value2...
- 2024-11-22 09:00Francek Chen的博客 本实验介绍掌握Hive分区的用法,加深对Hive分区概念的理解,了解Hive表在HDFS的存储目录结构。
- 2023-03-14 20:04yiluohan0307的博客 对于一张表或者分区,...答案是二级分区表,例如可以在按天分区的基础上,再对每天的数据按小时进行分区。命令后,分区元数据会被删除,而HDFS的分区路径不会被删除,同样会导致Hive的元数据和HDFS的分区路径不一致。
- 2019-07-14 23:11大富的大数据之路的博客 动态分区基于hive的源数据表将数据插入到分区表中,在数据插入的时候会根据分区字段自动将数据归类存入对应的分区路径,不需要手动指定分区 注意:系统默认以最后一个字段为分区名,因为分区表的分区字段默认也是该...
- 没有解决我的问题, 去提问

